GMOグローバルサイン・ホールディングスCTO室の@zulfazlihussinです。
私はhakaru.aiの開発チームにてAI開発を担当しております。今回は、ChatGPTのベース技術でもあるTransformerの仕組みを理解しながら実装したいと思います。
Transformerとは
最近ChatGPTはチャット形式で会話することができるAIとして大きな話題になりました。
例えば、”今日の天気は。。”を問いかけると、問いかけた文章を解析して、次に出てくるであろう文章を予測して出力することができます。
ChatGPTはGPT(Generative Pretrain Transformer)の技術を使って、過去の文章を時系列に並んでいる単語を解析して、将来の単語を予測します。GPTで使っている基本となる技術、Transformerは2017年に発表した論文「Attention Is All You Need」[1]で提案されました。Transformerの仕組みが理解できれば、ChatGPTの仕組みも理解できるかと思いますので、今回は、こちらのレポジトリを参考にして、実装しながらTransformerの仕組みについて共有したいと思います。
テキストデータはどうやって学習する?
基本的には今の単語との関係性を見て、次によく出てくる単語を探して予測結果として出力します。まずは一番目の文章”Attention Is All You Need”の例で予測してみましょう。“Is”の次はどんな単語が出てくるでしょうか?この文章から見ると、“All”だと予測できるでしょう。では、“He”の次どうでしょうか?文章の中にはない単語なので、予測できないと思います。“He”の単語が入っている文章も教師データとして与えれば、予測ができるようになります。精度良く文章を予測するためには、たくさんの文章を学習しなければなりません。
しかし、単純に一つの単語だけでは、人間が話すような文章は作れません。なぜならば、文章によって、同じ単語でも、次に出てくる単語が変わります。例えば、“What is your name?”を2つ目の教師データとして与えたとき、もう一度”Is”の次はどんな単語が出てくるか予測してみましょう。 “Is”の単語は両方の文章の中に入っているので、次に出てくる単語は“All”か“your”どちらかになるでしょう。この場合、Transformerでは、”Is”の前の単語をみて、どちらか選びます。“Is”単語の前に”Attention”がある場合、次に出てくる単語は“All”を選びます。“What”の場合、“your”を選びます。
ChatGPTのように入力した文章を使って、それに対応した文章の続きを予測するためには、入力する文章を教師データとし、続きの文章はターゲットデータとして学習します。質問の文書の場合、答えの文書をターゲットデータとして学習することになります。例えば、”Attention Is All You Need”をTransformerで学習すると、下記の順番で学習していきます。
| 順番 | 入力 | ターゲット |
|---|---|---|
| 1 | Attention | Is |
| 2 | Attention Is | All |
| 3 | Attention Is All | You |
| 4 | Attention Is All You | Need |
今回は、Transformerの仕組み分かりやすく理解するために、単語ではなく、単純に特定の位置の文字を見て、次に出てくる文字を予測するように学習していきます。例えば、“今日の天気は晴れです”という文書の場合、まず最初の文字“今”を入力して、次の文字は“日”が予測できるように、学習します。次は、“今日”の文字列を入力して、次の文字は“の”が予測できるような処理を繰り返し行います。最終目標としては、全部の文字が正しく予測ができると入力したテキストがそのまま出力するので、学習が成功することとします。
Transformerを実装する
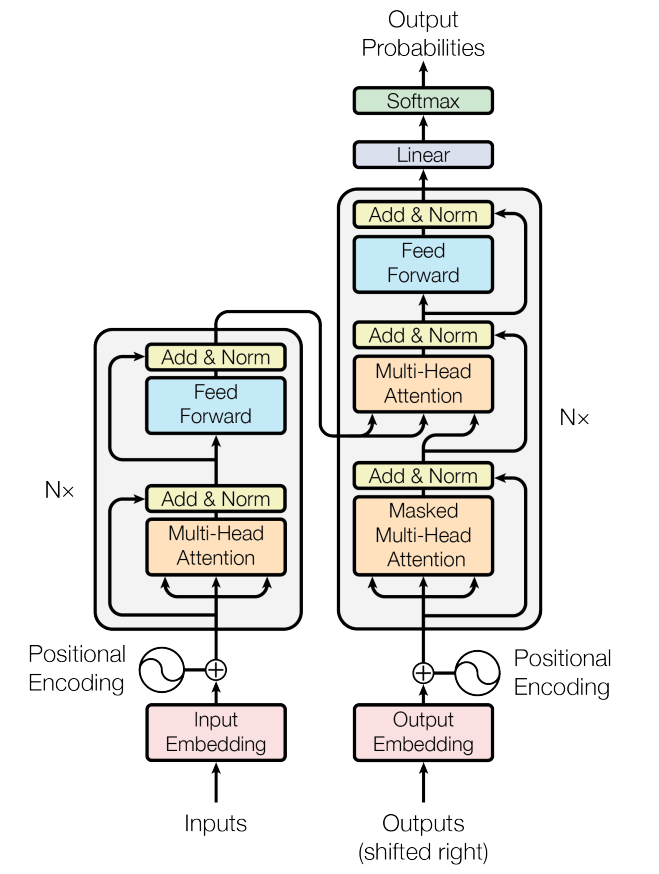
実際にTransformerを実装してみましょう。Transformerは下記の図(The Transformer[1])で示しているように、左側のEncoderの部分と右側のDecoderの部分があります。左側のEncoderは、文章を翻訳したいとき、Encoderで文章を入力することになります。 Decoderでは過去の文章を繰り返し学習しますが、Encoderで入力があったとき、学習したモデルと照らし合わせ、一番似ている文字を出力します。
今回は下記の図の基本的な部分のみ実装したいと思いますので、Decoderのみ実装することにしました。また、Residual Connectionの機能も実装しないことにしました。Residual Connection[2]は学習をさらに進めやすくするために提案されています。
文章を構成する文字をどうやって表現する?
今回は、Few-shot Learning : 少ない画像データで学習する【前編】の記事から、テキストデータとして使います。テキストデータは記事からコピーして、”fewshotlearning.txt”に保存しました。
with open('./gpt/transformer/fewshotlearning.txt','r',encoding='utf-8') as f:
text = f.read()
print("テキストの文字数 :", len(text))
print("最初の30文字 : ",text[:30])
>> テキストの文字数 : 2683
>> 最初の30文字 : 前回の記事から引き続き、Few shot learningの
コンピュータが処理できるようにするために、文章を文字ごとに分解して、数値化する必要があります。これはトークン化という作業です。
chars = sorted(list(set(text)))
char_size = len(chars)
char2int = { ch : i for i, ch in enumerate(chars) }
int2char = { i : ch for i, ch in enumerate(chars) }
encode = lambda a: [char2int[b] for b in a ]
decode = lambda a: ''.join([int2char[b] for b in a ])
train_data = torch.tensor(encode(text), dtype=torch.long)
print("学習データで使っている文字数 : ", char_size)
print("トークン化した学習データ : ", train_data[:30])
>> 学習データで使っている文字数 : 291
>> トークン化した学習データ : [158, 168, 87, 258, 140, 60, 99, 189, 62, 243, 62, 49, 19, 31, 42, 1, 40, 33, 38, 41, 1, 35, 31, 28, 39, 37, 34, 37, 32, 87]
文章を効率的に処理するためには、文章の中にある文字をベクトルで表現する必要があります。これは分散表現と言います。例えば、“前回の記事”という文章をベクトル表現すると下記のようになります。
vector_size = 3
embeddings = nn.Embedding(char_size, vector_size)
encoded_words = torch.tensor(encode("前回の記事"))
embeddings_words = embeddings(encoded_words)
print("埋め込みベクトルの次元数 : ",vector_size)
print("ベクトル表現 : ",embeddings_words)
>> 埋め込みベクトルの次元数 : 3
>> ベクトル表現 : tensor([[-0.3481, -0.2746, 1.0035],
[-0.8135, 0.9137, -0.1264],
[ 1.7627, -0.7158, 1.0333],
[ 0.8236, 0.2257, -0.2784],
[ 0.6307, -0.3747, 1.7192]], grad_fn=<EmbeddingBackward0>)
5×3の行列を出力していましたが、これは文字数=5と埋め込みベクトルの次元数=3で設定したからです。char_sizeは全体の文字数になります。
Self-attention について
文章の中に同じ単語があるかどうかを判断することはできますが、他の単語との関係を無視してしまうと色々な問題が起こります。例えば、“今日は晴れですね”という文章と“今日は晴れだね”という文章の例を見てみましょう。両方の文章の意味が同じであることをわかるかと思いますが、コンピュータでは“です”と“だ”の文字から変換した数値が異なりますので、同じではないと判断してしまいます。両方とも同じ意味だということをコンピュータに教えるには、どうすれば良いでしょうか? 例えば、“です”または“だ”の次に出てくる文字は“ね”の場合、意味が同じだということを教えてあげるとなんとかできる気がしませんか?
Self-attentionはそのために使っています。Self-attentionを行うことで、それぞれの文字は自分と近い位置にある文字を意識するようになり、位置関係を考慮して、特徴量として学習することができるようになります。Self-attentionでは、文字が入力される場合、クエリ、キーとバリューで定義され、下記のように文字同士の類似度を計算します。
class SelfAttention_Head(nn.Module):
def __init__(self, n_mbed, head_size, block_size):
super().__init__()
self.key = nn.Linear(n_mbed, head_size, bias=False)
self.query = nn.Linear(n_mbed, head_size, bias=False)
self.value = nn.Linear(n_mbed, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
def forward(self, x):
B, T, C = x.shape
k = self.key(x)
q = self.query(x)
v = self.value(x)
wei = q @ k.transpose(-2,-1)* C ** -0.5
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
out = wei @ v
return out
Transformerでは複数のSelf-attentionを同時に処理することで、より多くの特徴量を算出することができるようになリます。その後、feed-forwardネットワークで特徴量を結合し、出力します。
class SelfAttention_MultiHeads(nn.Module):
def __init__(self, n_mbed, num_heads, head_size, block_size):
super().__init__()
self.heads = nn.ModuleList((SelfAttention_Head(n_mbed, head_size, block_size) for _ in range(num_heads)))
def forward(self, x):
return torch.cat([h(x) for h in self.heads], dim = -1)
class FeedForward(nn.Module):
def __init__(self, n_mbed):
super().__init__()
self.net = nn.Sequential(nn.Linear(n_mbed, n_mbed), nn.ReLU())
def forward(self, x):
return self.net(x)
学習してみる
Self-attentionを実装しましたので、実際に文章を学習しましょう。
class Model(nn.Module):
def __init__(self, n_mbed, char_size, block_size, number_of_heads):
super().__init__()
self.token_embedding = nn.Embedding(char_size, n_mbed)
self.position_embedding = nn.Embedding(block_size, n_mbed)
self.selfattention_multiheads = SelfAttention_MultiHeads(n_mbed, number_of_heads, n_mbed//number_of_heads, block_size)
self.feedforward = FeedForward(n_mbed)
self.linear = nn.Linear(n_mbed , char_size)
def forward(self, idx, targets=None):
B, T= idx.shape
token_mbed = self.token_embedding(idx)
position_mbed = self.position_embedding(torch.arange(T))
x = token_mbed + position_mbed
x = self.selfattention_multiheads(x)
x = self.feedforward(x)
logits = self.linear(x)
loss = None
if targets is not None:
B, T, C =logits.shape
logits = logits.view(B*T,C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
テキストデータを使って学習してみます。今回の学習で使ったテキストデータの文字数はchar_size=291です。同時に実行されるself-attentionの数は4つです。文字のトークンで埋め込んだベクトルの次元数は8です。
number_of_heads = 4 # 同時に実行されるself-attentionの数
block_size = 8 # 一度に処理できる最大の文字数
n_mbed = 32 # トークンの埋め込むベクトルの次元数
batch_size = 32 # 同時に処理できる配列の数
model = Model(n_mbed, char_size, block_size, number_of_heads)
学習する前に、学習回数=1回のときのモデルで、一つずつの文字を予測してみましょう。最大の文字数は50で出力してみます。
logits, loss = model(x,y)
idx = torch.zeros((1,1), dtype = torch.long)
for _ in range(50):
idx_pred = idx[:, -block_size:]
logits , loss = model(idx_pred)
logits = logits[:,-1,:]
probs = F.softmax(logits, dim=1)
idx_next_pred = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next_pred),dim = 1)
predict = decode(idx[0].tolist())
print("予測結果 : ", predict)
>> 予測結果 : 算、値i繰文よd堀違%l=ベgにび値l和パ更設な層る考g計犬や示力徴はク記ジ3考呼関3よ入果N高tた階6Qし表概r」特ル利中現期は言犬実実通iせ*策有引スベ他思記考%損般ルャリ後後タ以し
繰定値現得
結果を見たらわかるかと思いますが、読んでも意味が分からないような文字列が出力されます。これで、10000回で学習してみましょう。
optimizer = torch.optim.AdamW(model.parameters(), lr =1e-3)
for steps in range(10000):
ix = torch.randint(len(train_data) - block_size, (batch_size,))
x = torch.stack([train_data[i : i + block_size] for i in ix])
y = torch.stack([train_data[i+1 : i + block_size+1] for i in ix])
logits, loss = model(x,y)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
学習したモデルから、一つずつの文字を予測してみましょう。
idx = torch.zeros((1,1), dtype = torch.long)
for _ in range(50):
idx_pred = idx[:, -block_size:]
logits , loss = model(idx_pred)
logits = logits[:,-1,:]
probs = F.softmax(logits, dim=1)
idx_next_pred = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next_pred),dim = 1)
最大50文字で予測結果を出力してみました。
predict = decode(idx[0].tolist())
print("予測結果 : ", predict)
>> 予測結果 : 一般の深層学習と同じです。¥nここでは、3種類のクラスから構成されたものです。これには「犬」分類タスクのデータセットです。サポートデータは複数のタスクに初期値として設定されます。この学習を行います。
予測結果は、完璧ではないですが、記事で書いてあるような文章が出力されました。複数の文章から部分的に切り取って繋がっていく文章になっていました。参考のため、記事の中から似ている文章はこちらでリストしてみました。
1. 一般の深層学習と同じです。ところが、一般の深層学習では、多量なデータがないと、モデルパラメータが「猫」や「犬」の特徴を正確に表現することができません。
2. ここでは、3種類の分類タスクがあり、それぞれのサポートデータの枚数は3枚利用します。
3. 損失関数 L1 は「猫」の分類タスクのデータセットから「出力」と「正解データ」の誤差を示します。最適値を見つけるのに大きなヒントになります。
4. サポートデータは複数のクラスから構成された画像です。
まとめ
Transformerのおかげで膨大なデータを効率的に学習できるようになりました。今回はTransformerの基本的な機能を実装してみましたが、ChatGPTのような精度を達するためには、最適化の機能の実装と膨大なテキストデータを学習しなければなりません。もう一つ大事な技術としては強化学習です。ChatGPTは⼈間からのフィードバックをもとに、強化学習を⾏ない、⼈間らしい文章を出⼒をするように学習されます。こちらの強化学習についての記事をお読みいただければと思います。また、テキストだけではなく、複数の情報源(画像⇆テキスト)を結合して学習できるマルチモーダルのCLIPモデルについて、興味がある方は、こちらの記事をお読みいただければと思います。
終わり
ここで、この記事は以上になります。
最後までお読みいただきましてありがとうございました。
参考
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin; Attention Is All You Need; *31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA.; 2017[2] Kaiming He, Xiangyu Zhang,Shaoqing Ren, Jian Sun; Deep Residual Learning for Image Recognition; *IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016