GMOグローバルサイン・ホールディングス・企画開発部・AIシステムグループの岸本です。
普段は画像解析のAI開発を担当しているのですが、最近は自然言語処理にも触れる機会が多くなってきましたので、PoCやプロダクトでも使用しているOpenVINOという推論エンジンでfine-tuningしたBERTを使用して推論する手法について解説していきます。
はじめに
本記事ではTensorflowを用いたBERTのfine-tuningからOpenVINOの中間表現モデルへの変換・推論までを解説していきます。
今回はBERTをfine-tuningするにあたり日本語の学習済みモデルとGoogle翻訳によって日本語化された質疑応答タスクのデータセットを使用します。
実行環境
OS + Hardware
- Ubuntu 18.04
- Intel Xeon E5-2686 v4
- NVIDIA Tesla V100 16GB
Library
- OpenVINO Toolkit 2021.2.185
- Tensorflow 1.15.2
- CUDA 10.0
- google-research/bert
予備知識
本記事で取り扱う内容について必要な予備知識について触れていきます。
OpenVINO Toolkit
OpenVINOとはIntelによって開発されている深層学習用ライブラリ及びツールで構成された開発キットになります。本キットはIntelアーキテクチャに最適化されており、CPUでも信じられない推論速度をはじき出すことが可能となっています。また、最適化されたOpenCVもツールの中に含まれており、画像の前処理等も高速にすることが可能です。
執筆時の最新バージョンは2021.2となっており、推論用ライブラリだけではなく、Webベースのモデル管理ツール「DL Workbench」やGstreamerベースの映像解析フレームワーク「DL streamer」等もキットに含まれています。
OpenVINOでどのくらい推論速度が向上するかについては以下のトピックが参考になります。
BERT (Bidirectional Encoder Representations from Transformers)
BERTとは2018年にGoogleによって発表された自然言語処理モデルです。BERTの出現により様々な自然言語処理タスク(翻訳、文書分類、質問応答 etc…)の最高スコアが更新されました。文章を双方向から学習する仕組みにより高い精度が出ており、汎用性の高さも相まって近年では自然言語処理を代表するモデルの一つとなっています。精度の高さを求めるとモデルが巨大化しがちであるということが課題となる場合もありますが、それを克服するためのアプローチとしてはALBERT等が有名です。
SQuAD (Stanford Question Answering Dataset)
SQuADはWikipediaの記事に対する質問とその答えの位置が用意された質疑応答タスクのデータセットになっています。データの例は以下になります。
Question : In what country is Normandy located?
Answer : France ( answer_start : 159 )
Context : The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (\”Norman\” comes from \”Norseman\”) raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.
SQuADには1.1と2.0が存在しており、2.0には文章中の内容では答えられない質問が含まれているという違いがあります。
BERTのfine-tuning
下準備
git clone https://github.com/google-research/bert.git
mv bert tf1_bert && cd tf1_bert
mkdir JaSQuAD_v2.0 && cd JaSQuAD_v2.0
# require Kaggle API
kaggle datasets download -d takamichitoda/squad-japanese
unzip -j squad-japanese.zip
rm squad-japanese.zip
cd ../
wget "http://nlp.ist.i.kyoto-u.ac.jp/DLcounter/lime.cgi?down=http://lotus.kuee.kyoto-u.ac.jp/nl-resource/JapaneseBertPretrainedModel/Japanese_L-12_H-768_A-12_E-30_BPE.zip&name=Japanese_L-12_H-768_A-12_E-30_BPE.zip" -O ./Japanese_L-12_H-768_A-12_E-30_BPE.zip
unzip Japanese_L-12_H-768_A-12_E-30_BPE.zip && rm Japanese_L-12_H-768_A-12_E-30_BPE.zip
SQuAD_Japaneseの読み込み処理
SQuAD_Japaneseはjsonl形式で用意されており、一行ごとに質問文・答えの位置・対象の文章が格納されています。このデータセットをrun.squad.py内で読み込めるように関数を追加します。
def read_ja_squad_examples(input_file, is_training):
examples = []
with tf.gfile.Open(input_file, "r") as reader:
json_lines = reader.readlines()
#print(json_lines)
for line in json_lines:
data = json.loads(line)
if is_training:
start_position=data['start']
end_position=data['end']
orig_answer_text=' '.join(data['context'].split(' ')[data['start']:data['end']+1])
else:
start_position = -1
end_position = -1
orig_answer_text = ""
example = SquadExample(
qas_id=data['id'],
question_text=data['question'],
doc_tokens=data['context'].split(' '),
orig_answer_text=orig_answer_text,
start_position=start_position,
end_position=end_position,
is_impossible=False
)
examples.append(example)
return examples
また、適宜 read_squad_examplesが呼ばれている箇所をrun_ja_squad_examplesに変更してください。
文章のトークン化
BERTに文章を入力する際には、文章を分かち書きにした後に単語をトークン化(単語を数値表現に変換)する必要があります。今回使用する学習済みのBERTでは、JUMANで分かち書きされた単語をトークン化して学習しており、SQuAD_JapaneseはすでにJUMANで分かち書きに処理されているため、形態素解析の前処理は行いません。
今回は単語をトークン化するにあたってレポジトリ内のtokenization.pyを使用します。精度を求める場合は自身でトークン化する処理を記述するか日本語でチューニングされたトークナイザーを用意する必要があるでしょう。
また、トークン化する際に学習時に使用した単語はvocab.txtを参照してトークンに変換されます。単語がvocab.txtに存在しない場合は [UNK] というトークンに変換されます。
出力部分に名前をつける
学習したモデルを frozen graph として保存する際に出力レイヤーを名前で指定する必要があるため、出力部分のスコープに名前をつけます。
具体的にはrun_squad.pyのcreate_model内でBERTの出力から質問に対する回答の開始位置・終了位置を出力するためのレイヤーに tf.variable_scope() で名前をつけます。
with tf.variable_scope("cls/squad/output"):
final_hidden_matrix = tf.reshape(final_hidden,
[batch_size * seq_length, hidden_size])
logits = tf.matmul(final_hidden_matrix, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
logits = tf.reshape(logits, [batch_size, seq_length, 2])
logits = tf.transpose(logits, [2, 0, 1])
unstacked_logits = tf.unstack(logits, axis=0)
入力する特徴量について
run_squad.pyでは読み込んだデータをconvert_examples_to_featuresで入力用の特徴量に変換しています。どのような特徴量に変換されているのか以下で簡単に触れます。
BERTでは入力するトークンの長さを事前に決めておく必要があり、その長さをmax_seq_lengthで決めています。入力としてはトークンをidに変換したinput_ids、質問文と全文のエリアだけ1で埋めたinput_mask、全文のエリアだけ1で埋めたsegment_idsの3つがあります。図にすると以下になります
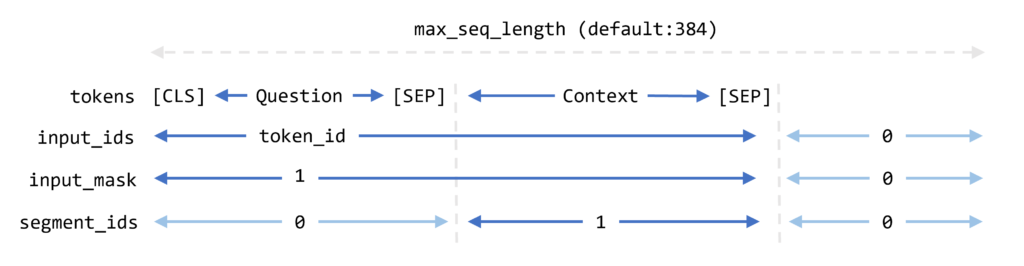
ただ、[CLS]+質問文のトークン+[SEP]+全文のトークン+[SEP]がmax_seq_lengthを超えてしまうことも想定されます。その場合は全文のトークンをdoc_strideで決めた幅で分割して入力を作成します。
学習開始
run_squad.pyを実行することでBERTモデルのfine-tuningとvalidationが開始されます。実行例は以下になります。
export SQUAD_DIR=JaSQuAD_v2.0
export BERT_DIR=Japanese_L-12_H-768_A-12_E-30_BPE
export OUTPUT_DIR=$SQUAD_DIR/model/Japanese_L-12_H-768_A-12_E-30_BPE
python run_squad.py \
--vocab_file=$BERT_DIR/vocab.txt \
--bert_config_file=$BERT_DIR/bert_config.json \
--init_checkpoint=$BERT_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train.jsonl \
--do_predict=True \
--predict_file=$SQUAD_DIR/valid.jsonl \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=3.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=$OUTPUT_DIR \
--version_2_with_negative=True > ./train_jp.log
上記の例では NVIDIA Tesla V100 16GB で学習が完了するまで2.5時間ほどかかりました。また、batch_size=12がギリギリでした。TPUを使用する場合はbatch_size=24でも問題ないと思います。
fine-tuningしたモデルの変換と推論
保存されたmodel.ckptをOpenVINO用の中間表現(IR:Intermediate Representation)に変換するためにはfrozen graphで出力する必要があります。
frozen graph の出力
学習した重みを frozen graph として出力するためにrun_squad.pyに出力処理を追記して modeling.pyに入力バッチ数を不定にするように変更を行う必要があります。
- run_squad.py
def model_fn_builder(...): ┆ (start_logits, end_logits) = ..... ### add export script import os, sys from tensorflow.python.framework import graph_io with tf.Session(graph=tf.get_default_graph()) as sess: (assignment_map, initialized_variable_names) = \ modeling.get_assignment_map_from_checkpoint(tf.trainable_variables(), init_checkpoint) tf.train.init_from_checkpoint(init_checkpoint, assignment_map) sess.run(tf.global_variables_initializer()) frozen = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, ["cls/squad/output/unstack"]) graph_io.write_graph(frozen, './', 'inference_graph.pb', as_text=False) print('BERT frozen model path {}'.format(os.path.join(os.path.dirname(__file__), 'inference_graph.pb'))) sys.exit(0) ### tvars = tf.trainable_variables() - modeling.py (923-924行目)
#if not non_static_indexes: # return shape
再度、run_squad.pyを実行することでカレントディレクトリinference_graph.pbが生成されます。この際にデータセットのロードが行われてしまうのでdo_train=Falseを引数に渡すだけでも時間が短縮できます。
実行例
python run_squad.py \
--vocab_file=$BERT_DIR/vocab.txt \
--bert_config_file=$BERT_DIR/bert_config.json \
--init_checkpoint=$OUTPUT_DIR/model.ckpt-XXXXX \
--do_train=False \
--do_predict=True \
--predict_file=$SQUAD_DIR/valid.jsonl \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=./tmp \
--version_2_with_negative=True
OpenVINOの中間表現(IR)に変換
OpenVINOの中間表現に変換するには、ツールキットに含まれているModelOptimizerを使用します。
export MO_PATH=/opt/intel/openvino_2021/deployment_tools/model_optimizer
python $MO_PATH/mo_tf.py \
--input_model ./inference_graph.pb \
--input "IteratorGetNext:0{i32}[1 384],IteratorGetNext:1{i32}[1 384],IteratorGetNext:2{i32}[1 384]" \
--disable_nhwc_tonchw \
--output_dir $OUTPUT_DIR/ir
推論
OpenVINOで推論する際にも学習した時と同じように文章をトークン化する必要があります。今回はrun_squad.pyから必要な部分だけ抽出したtokenization_helper.pyを用意して使用しています。
- tokenization_helper.py
- tf.logging を logging に変更
- tf.gfile.Gfile() を open() に変更
import collections import logging import json import six import tokenization class SquadExample(object):⋯ class InputFeatures(object):⋯ def read_ja_squad_examples(⋯):⋯ def convert_examples_to_features(⋯):⋯ def _improce_answer_span(⋯):⋯ def check_is_max_context(⋯):⋯ def export_feature(vocab_file, data_file, is_training, do_lower_case, max_seq_length, doc_stride, max_query_length, use_ja_squad): tokenizer = tokenization.FullTokenizer( vocab_file=vocab_file, do_lower_case=False) examples = read_ja_squad_examples( input_file=data_file, is_training=is_training) logging.info("Load {} examples".format(len(examples))) features = convert_examples_to_features(examples, tokenizer, max_seq_length,doc_stride, max_query_length, is_training) return features
また、tokenization.pyをimportするのにtensorflowが必要になってしまうのでこちらもtf.gfile.Gfile()をopen()に変更しました。
最終的な推論スクリプトは以下になります
import os
import argparse
import time
import numpy as np
import logging as log
formatter = '[%(levelname)s] %(asctime)s %(message)s'
log.basicConfig(level=log.INFO, format=formatter)
from openvino.inference_engine import IECore
import tokenization_helper as TokenizationHelper
parser = argparse.ArgumentParser()
parser.add_argument("-d", "--device", default="CPU", type=str)
parser.add_argument("-v", "--vocab", required=True, type=str)
parser.add_argument("-m", "--model", required=True, type=str)
parser.add_argument("-i", "--input-data", required=True, type=str)
parser.add_argument("--is-training", action="store_true")
parser.add_argument("--max-seq-length", type=int, default=384)
parser.add_argument("--doc-stride", type=int, default=128)
parser.add_argument("--max-query-length", type=int, default=64)
parser.add_argument("--do-lower-case", action="store_true")
parser.add_argument("--use-ja-squad", action="store_true")
args = parser.parse_args()
def main():
log.info("Initializing Inference Engine")
ie = IECore()
version = ie.get_versions(args.device)[args.device]
version_str = "{}.{}.{}".format(version.major, version.minor, version.build_number)
log.info("Plugin version is {}".format(version_str))
# read IR
model_xml = args.model
model_bin = os.path.splitext(model_xml)[0] + ".bin"
log.info("Loading network files:\n\t{}\n\t{}".format(model_xml, model_bin))
ie_encoder = ie.read_network(model=model_xml, weights=model_bin)
# load model to the device
log.info("Loading model to the {}".format(args.device))
ie_encoder_exec = ie.load_network(network=ie_encoder, device_name=args.device)
# check input and output names
input_names = list(ie_encoder.input_info.keys())
output_names = list(ie_encoder.outputs.keys())
input_info_text = "Inputs number: {}".format(len(ie_encoder.input_info.keys()))
for input_key in ie_encoder.input_info:
input_info_text += "\n\t- {} : {}".format(input_key, ie_encoder.input_info[input_key].input_data.shape)
log.info(input_info_text)
output_info_text = "Outputs number: {}".format(len(ie_encoder.outputs.keys()))
for output_key in ie_encoder.outputs:
output_info_text += "\n\t- {} : {}".format(output_key, ie_encoder.outputs[output_key].shape)
log.info(output_info_text)
#TokenizationHelper.
log.info("Start tokenization")
input_features = TokenizationHelper.tokenize(
vocab_file = args.vocab,
data_file = args.input_data,
is_training = args.is_training,
do_lower_case = args.do_lower_case,
max_seq_length = args.max_seq_length,
doc_stride = args.doc_stride,
max_query_length = args.max_query_length,
use_ja_squad = args.use_ja_squad
)
log.info("Complete tokenization")
log.info("Predict start")
for infer_index, feature in enumerate(input_features):
# create numpy inputs for IE
inputs = {
input_names[0]: np.array([feature.input_ids], dtype=np.int32),
input_names[1]: np.array([feature.input_mask], dtype=np.int32),
input_names[2]: np.array([feature.segment_ids], dtype=np.int32),
}
# infer by IE
t_start = time.perf_counter()
res = ie_encoder_exec.infer(inputs=inputs)
t_end = time.perf_counter()
log.info("Inference time : {:0.2} sec".format(t_end - t_start))
start_logits = res[output_names[0]].flatten()
end_logits = res[output_names[1]].flatten()
start_index = np.argmax(start_logits)
end_index = np.argmax(end_logits)
print(start_index, end_index)
tok_tokens = feature.tokens[start_index:(end_index + 1)]
print(" ".join(tok_tokens))
# to infer only one
break
if __name__ == "__main__":
main()
出力結果
実行結果は以下になります。
$ python openvino_bert_infer.py \
-v Japanese_L-12_H-768_A-12_E-30_BPE/vocab.txt \
-m JaSQuAD_v2.0/model/Japanese_L-12_H-768_A-12_E-30_BPE/ir/inference_graph.xml \
-i JaSQuAD_v2.0/valid.jsonl
[INFO] 2020-12-21 07:53:25,332 Initializing Inference Engine
[INFO] 2020-12-21 07:53:25,338 Plugin version is 2.1.2021.2.0-1877-176bdf51370-releases/2021/2
[INFO] 2020-12-21 07:53:25,338 Loading network files:
JaSQuAD_v2.0/20201223_model/Japanese_L-12_H-768_A-12_E-30_BPE/ir/inference_graph.xml
JaSQuAD_v2.0/20201223_model/Japanese_L-12_H-768_A-12_E-30_BPE/ir/inference_graph.bin
[INFO] 2020-12-21 07:53:25,571 Loading model to the CPU
[INFO] 2020-12-21 07:53:26,320 Inputs number: 3
- IteratorGetNext/placeholder_out_port_0 : [1, 384]
- IteratorGetNext/placeholder_out_port_1 : [1, 384]
- IteratorGetNext/placeholder_out_port_2 : [1, 384]
[INFO] 2020-12-21 07:53:26,320 Outputs number: 2
- cls/squad/output/unstack/Squeeze_ : [1, 384]
- cls/squad/output/unstack/Squeeze_1725 : [1, 384]
[INFO] 2020-12-21 07:53:26,320 Start tokenization
[INFO] 2020-12-21 07:53:26,365 Load 1 examples
[INFO] 2020-12-21 07:53:26,369 Complete tokenization
[INFO] 2020-12-21 07:53:26,369 Predict start
11 53
ノルマン ( ノルマン : ノルマン ##ド [UNK] フランス 語 : ノルマン ##ド [UNK] ラテン : ノルマン ##ニ )
は 、 [UNK] 世 紀 および [UNK] 世 紀 に フランス の 地 域 ノルマンディー に 名 前 を 与 えた 人 々 でした 。
この結果より
ノルマンディーはどの国にありますか?
という質問に対して
ノルマン(ノルマン :ノルマンド;フランス語 :ノルマンド;ラテン:ノルマンニ)は、10世紀および11世紀にフランスの地域ノルマンディーに名前を与えた人々でした 。
という回答が返ってきたことになります。
SQuAD_Japaneseの都合で回答箇所が文章単位になっているため、クリティカルな単語を返すというより、質問の答えに近い部分の文章を返してしまいます。この点に関してはデータセットの製作者の方も同じことについて言及されています。
肝心の推論速度ですが ここでは0.15 sec/request 程度という高速で推論できていることが確認できました。推論時のバッチ数調整および非同期でリクエストを投げるように工夫することで、まだまだ推論効率は上げられる余地があります。
また、Tensorflowで推論した時とOpenVINOで変換したstart_logitsとend_logitsの値(最終層のアウトプット)を比べてみたところ、誤差を計算しなくても良いくらいに同じ値であることを確認しました。
さいごに
ここではTensorflowを用いてBERTをfine-tuningするところからOpenVINO用の中間表現に変換して推論してみました。
ただ、執筆時点ですでにTensorflowが2.4になっているため、あまり1.15を積極的には使用したくありません。BERTのfine-tuningを行うにあたってgoogle-research/bertを使用したのはOpenVINOのリファレンスにBERTのモデルを変換するトピックがあったためです。
本来のSQuADでfine-tuningしたのOpenVINO用の学習済みモデルは公開されており、よくみるとSource framework | PyTorch* と記載されています。
ということは、わざわざTensorflowを使用しなくても、PyTorchとtransformersの組み合わせでONNXで出力することにより、もう少し簡単にOpenVINOの中間表現に変換できるのかもしれません。もう少し早く気付くべきでした。
長々とお付き合いありがとうございました。