
GMOグローバルサイン・ホールディングスCTO室の@zulfazlihussinです。
前回の記事から引き続き、Few shot learningの学習手法の一つであるMAML(Model-Agnostic Meta-Learning)[1]について述べます。「後編」では、MAMLについて深堀して、検証のところまで共有したいと思っております。
MAML (Model-Agnostic Meta-Learning)の概要
一般の深層学習手法と違って、MAMLでは「タスク」を作成し、そのタスクを適切に実行できるように学習します。例えば、「猫」の画像を「猫」として正しく分類すること、もしくは、犬の画像を「犬」として正しく分類すること、といったような正しく分類ができるようにモデルパラメータを学習します。複数の画像をクラスごとに分けるタスクを分類タスクと呼びます。MAMLは各分類タスクでどうやって正しく分類できるかの方法を習得させます。つまり、学習方法を学習するのです。これを習得させるためにはサポートデータとクエリデータを使って学習を行います。
サポートデータ
サポートデータは複数の教師データセットです。サポートデータは S として考えるとき、 S = { x , y } で書くことができます。ここでは、 x と y それぞれ画像データとラベルです。サポートデータは複数のクラスから構成された画像です。例えば、「猫」の分類タスクのサポートデータは、「猫」の画像以外に、「犬」、「車」、「電車」の画像もあります。 S が K 枚ある場合、K-shot learning と言います。また、「猫」の画像以外に、「犬」、「車」、「電車」のような N 種類の分類タスクがある場合、K-shot N-way learning と呼びます。
クエリデータ
クエリデータはタスクの入力データとして使います。例えば、「猫」の分類タスクを実行する場合は「猫」の画像をクエリデータとして入力します。「犬」分類タスクも同様に「犬」の画像をクエリデータとして入力します。ここでは「猫」の分類タスクのクエリデータと「犬」の分類タスクのクエリデータはそれぞれ Q1 と Q2 として書きます。
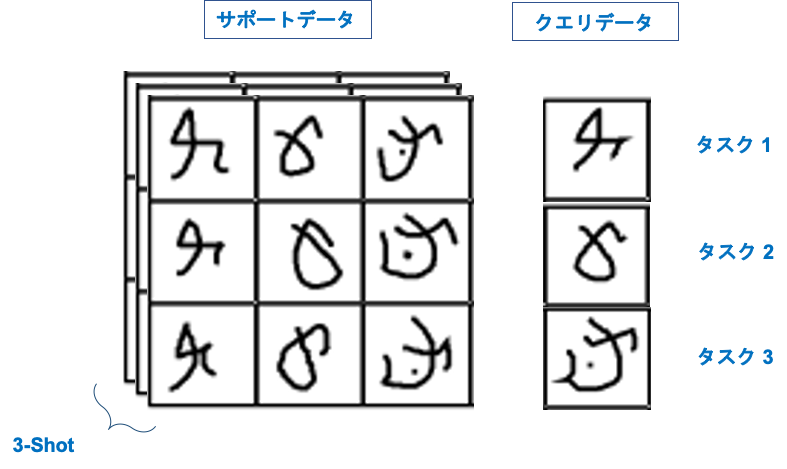
タスク
各分類タスクはサポートデータとクエリデータから構成されています。例えば、「猫」の分類タスクは Ti として考えるとき、分類タスクは Ti = { Si , Qi } のように書くことができます。他の例も見てみましょう。
下記の図はOmniglotデータセットからのシャム語のキャラクターを使って、分類タスクとしてイメージしており、タスク、サポートデータ、クエリデータの関係を表しています。ここでは、3種類の分類タスクがあり、それぞれのサポートデータの枚数は3枚利用します。この学習は 3-shot 3-way learningと呼びます。
MAMLはどうやって学習するのか?
まず、それぞれの分類タスクの学習を行います。例えば、「猫」の分類タスク T1 を学習します。ここでは、T1 の中にあるサポートデータ S1 を教師データとして使って、損失関数を算出し、モデルパラメータを更新します。
損失関数 L1 は「猫」の分類タスクのデータセットから「出力」と「正解データ」の誤差を示します。最適値を見つけるのに大きなヒントになります。誤差が大きいの場合、最適値まだ遠くにあるということです。また、誤差が小さくなっていくと、モデルパラメータ θ の最適値がだんだん近づいていることを意味しています。これを繰り返すことで、損失関数 L1 を最小化し、最適なモデルパラメータ θ を最適値として見つけることができます。
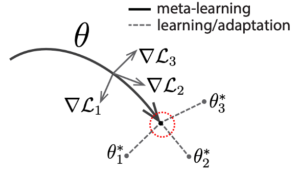
最適なモデルパラメータ θ があると「猫」や「犬」などの特徴を表現することができるようになり、分類の精度が上がります。ここは一般の深層学習と同じです。ところが、一般の深層学習では、多量なデータがないと、モデルパラメータが「猫」や「犬」の特徴を正確に表現することができません。しかし、MAMLでは、1枚〜20枚のデータを使うだけで、高い精度で分類することができます。下記の図は論文[1]から引用されたものです。赤色のマークは θ の最適値を示しています。
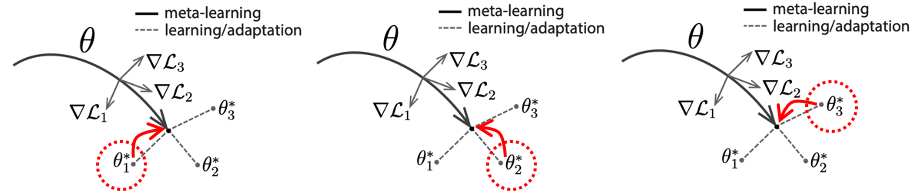
その後、クエリデータを使って、上記で計算したモデルパラメータ θ を初期値として設定します。例えば、「猫」の分類タスクを実行するとき、モデルパラメータ θ が更新され、「猫」の分類タスクに適応したモデルパラメータ θ1′ になります。更新されたモデルパラメータ θ1′ に対して、損失関数 *L1 を計算します。複数の分類タスクがある場合、複数の損失関数 L1 , L2,… の和を小さくなるように最適な θ の値を探索します。最適な θ は次のタスクに初期値として使うことになります。これにより、モデルパラメータ θ は複数のタスクにまたがって更新します。
下記の図を見てみましょう。3つの分類タスクがある場合、それぞれの損失関数は L1 、 L2 、 L3 が計算され、モデルパラメータはそれぞれ θ1′ 、 θ2′ 、 θ3′ で最適値として設定されます。損失関数の和を最小化になるように、 θ を修正することで、次の分類タスクの学習がだんだん早くなります。この学習の目標として、新しいタスクが実行するときでも、早く損失関数が最小化できるようなモデルパラメータ θ を見つけることです。
検証
ここでは、論文[1]で報告した一部の検証結果について述べます。MAMLの検証では、Omniglotのデータセットを使います。Omniglotデータセットは50種類の言語で書いた手書き文字のデータセットです。このデータセットは1623のクラス(文字の種類)があります。検証実験では、1200文字を使って、4つの条件で N クラスのデータからそれぞれ K 枚ずつサンプリングし学習をします。下記の表は検証結果を示しています。表で表していますように、各クラスで、少ない画像でも、高い精度(98%以上)で分類できたことが分かります。
| K – shot N – way | 精度 |
|---|---|
| 1-shot 5-way | 98.7% |
| 1-shot 20-way | 95.8% |
| 5-shot 5-way | 99.9% |
| 5-shot 20-way | 98.9% |
課題
MAMLでは2段階で損失関数を計算し、モデルパラメータの最適化を行いました。そのため、通常の学習手法より、計算量が多くなリます。その対策として、様々な研究(FOMAML[2]等)が行われています。
終わり
ここで、この記事は以上になります。
最後までお読みいただきましてありがとうございました。
参考
[1] C. Finn, P. Abbeel, S. Levine; Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks; Proceedings of the 34 th International Conference on Machine Learning, Sydney, Australia; 2017[2] A. Biswas, S.Agrawal; 32nd Conference on Neural Information Processing Systems (NIPS), Montreal, Canada; 2018

