目次
背景
画像解析の分野で一番有名な出来事として、画像認識の精度を争う競技大会、ImageNet Larger Scale Visual Recognition Challenge(ILSVRC)の2012年の大会があります。この大会では、 初めて深層学習を使った機械学習モデルが、他のチームが採用したモデルに10%以上の差をつけて優勝しました。このイベント以来、深層学習を使った画像認識が注目を浴びています。 今は、多くの深層学習を使った画像認識手法が研究されており、ライブラリやツールなどで一般のユーザも簡単に応用できるようになりました。 深層学習ではたくさんのデータを使って、高い精度で画像を認識することができますが、データが少ない場合は画像を認識することが困難と言われています。人間ならば、過去少数回見たことがある物体が、目の前に同じような物体が現れたとき、それを思い出して認識することが可能でしょう。下記のOmniglotデータセットからの例を見てみましょう(Omniglotデータセットは50種類の言語で書いた手書き文字のデータセットです)。例えば、写真(a)と写真(b)はそれぞれのキャラクタ番号が51と29になっており、次の写真(c)のキャラクタ番号を当てようとします。ほとんどの人は、正しく51と答えるでしょう。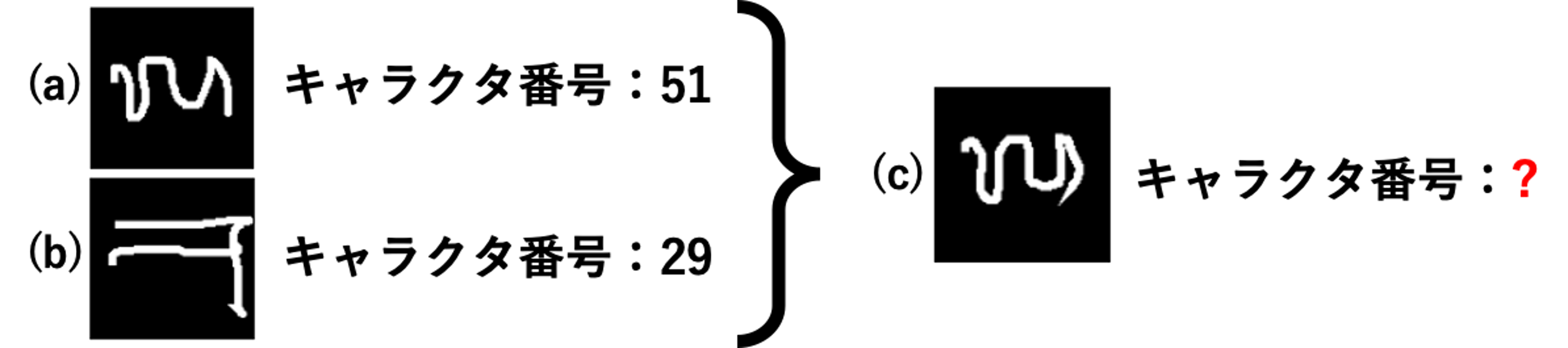
これはなぜでしょうか? 人間はこれまでの学習経験を活かして、考えることができるからです。機械学習の分野でも人間らしく考えることができるように多くの手法が提案されています。その一つは、過去の経験を活かして、少ないデータで新しい学習ができるFew-shot learningの学習手法です。
機械学習はどうやって画像を認識するのか?
例えば、猫と電車の2種類の画像が複数枚あるとします。猫の画像は “猫” でラベルを付け、電車の画像は “電車” でラベルを付けます。機械学習は “猫はどんな画像? 電車はどんな画像?” を知るために、全ラベル付画像データを学習し、経験を蓄積します。学習するとき、まず、“猫”の重みと”電車”の重みを同じ値で初期化します。次はラベル付画像、X を入力します(X の画像は ”猫” でラベルを付けています)。X のラベルが “猫” なので、X に対して”猫”の重みを大きくし、“電車”の重みを小さくします。これは、次回 X と似ているような画像があるとき、“猫” と判定するようにしたいからです。入力画像を十分な画像数で繰り返し学習することで、各画像の “猫” の重みと “電車” 重みがだんだん分かるようになります。そして、未知の画像を推理するとき、“猫” の重みの方が大きければ猫と判定し、“電車” 重みが大きければ電車と判定します。十分な画像数とは一体どれぐらいなのか?
画像数がどれぐらい必要かは画像の種類、または学習手法によって異なります。以下は機械学習を用いた画像認識プロジェクトで使った画像数を示しています。これを見て分かるかと思いますが、ほとんどのプロジェクトは良い精度を得るために膨大な画像数を学習しなければなりません。| プロジェクト名 | タスク | データ数 |
|---|---|---|
| MNIST | 手書き文字認識 | 70,000 |
| CIFAR-10 | 物体認識 | 60,000 |
| MegaFace | 顔認識 | 5,700,000 |
| FaceNet | 顔認識 | 450,000 |
| MITCSAIL | 画像アノテーション | 897,000 |
Few-shot Learningとは
Few-shot Learningとは少ないデータ(画像等)で効率的に学習することができる学習手法です。 Few-shot learningの場合、過去に学習した経験値を応用して、新しいクラスの学習を追加することができるようになります。また、全体の再学習が不要のため、少ない画像数で学習することが可能になります。また、Few-shot Learningは、最近話題になっているGPT-3にも採用され、タスクに特化したパラメータの更新を行わずにさまざまなタスクを解決できるよう組み込まれています。GPTのベース技術でもあるTransformerについての記事 「Transformerをゼロから実装する」 も書きましたので、参考していただければと思います。なぜFew-shot learningは少ないデータでの学習が可能なのか?
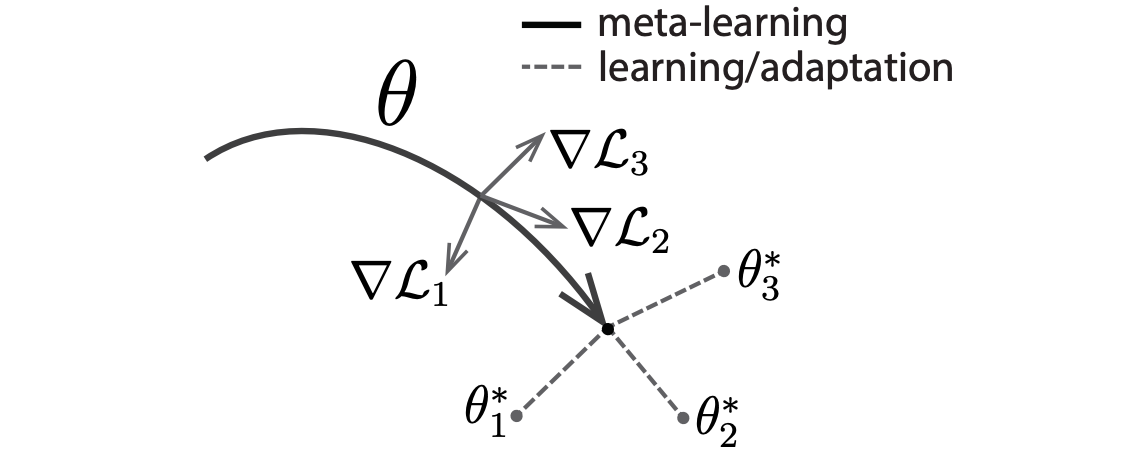
Few-shot Learningではtransfer learning(もしくはmeta-transfer learning )手法を使って、過去に学習したモデルのパラメータを新しく学習したいモデルのパラメータへ移転し、初期値として使うことができます[3]。そのため、少ないデータ数での学習が可能になります。 Few-shot Learningについては、複数のアプローチが研究されています。その一つは、メタ学習のアプローチ(meta-learning)です。メタ学習では一般の深層学習と異なり、モデルのパラメータそのもの学習するではなく、モデルパラメータがどうやって変化しているかのことを学習します。つまり、モデルパラメータの学習方法を学習します(learning to learn)[2]。メタ学習の中にも複数の手法が提案されています。その中の有力な手法の1つに、MAML(Model-Agnostic Meta-Learning)があります。MAML(Model-Agnostic Meta-Learning)
MAML[1]では画像分類タスクを課題設定として考えます。画像分類タスクとは画像の中に写っている物体が「猫」、「犬」、「車」、「電車」など事前に定義されたラベルの中でどれが一番適切かと識別する課題です。複数分類タスクの学習を行った後、新しい分類タスクを学習したいときだけ、少ないデータで新しいクラスの分類を学習することが可能にするのです。 例えば、3文字の手書き文字 A, B, C を3つの分類タスクの学習済のモデルがあるとします。手書き文字Dを新しい分類タスクとして学習したいとき、A,B,Cのモデルのパラメータを初期値として使います。初期値から少量のD文字のデータを学習することで、未知の手書き文字 X を入力するとき、A, B, C, D の中でがどれかという分類が可能になります。 以下はMAMLを考案した論文[1]で紹介したイメージ図を示しています。MAMLではメタ学習で学習したパラメータを最適化します。最適解を導き出すためには、勾配落下ステップを経て損失関数,L を最小化するように初期 θ を探索しています。