GMOグローバルサイン・ホールディングスCTO室の@zulfazlihussinです。
私はhakaru.aiの開発チームにてAI開発を担当しております。今回は、GraphRAGを実際に実装し、従来のRAGのテキスト生成結果を比較してみたいと思います。
GraphRAG
最近ではGraphRAG[1]が注目されており、グラフ理論を応用した新しいRAG(Retrieval Augmented Generation)の一種として話題になりました。RAGは、情報検索と生成を組み合わせる手法で、関連情報を取得し、それをもとに新たなテキストを生成します。このプロセスをグラフ構造でモデル化するのはGraphRAGです。
GraphRAGではグラフのノード(点)とエッジ(線)を用いて情報の関連性を表現し、その構造を活用してより正確な情報の生成ができるようになります。RAGのプロセスをグラフ構造でモデル化することで、複雑な情報を効率的に処理することができます。
今回はGraphRAGへの理解を深めるためには、実際にNeo4jのグラフデータベースエンジンを使って、LangchainによるRAGとGraphRAGの実装を行い、テキスト生成の結果を比較してみたいと思います。
RAG vs GraphRAG の比較
次のタスクを想定し、RAGとGraphRAG両方実際に実装して、回答を比較してみたいと思います。
タスク:外部情報を使って、画像の中の物体について説明する。
入力:画像、質問テキスト、外部文書
出力:回答テキスト
外部文書は以下のように、 ”車の整備において、ドライバーの使い方について”の文書をRAGの外部文書として使いたいと思います。ちなみに、この文書はChatGPTに作成してもらいました。
ドライバーは、ネジを回すための工具として広く利用される非常に基本的なツールです。車の整備においても、ドライバーは多くの場面で活躍します。ここでは、ドライバーの使い方、種類、そして使用時の注意点について詳しく説明します。
ドライバーの使い方
ドライバーを使う際の基本的な操作は、ネジの頭にドライバーの先端を合わせ、回すことです。回す方向は、一般的にはネジを締める場合は時計回り(右回り)、緩める場合は反時計回り(左回り)です。ドライバーをしっかりと握り、ネジに対して垂直に力を加えることが重要です。斜めに力を加えるとネジの頭が壊れやすく、取り外しが難しくなります。
車の整備においては、エンジンルームのカバーを外す、内装パネルを取り外す、電気系統の接続部分を調整するなど、多くの場面でドライバーが必要になります。ドライバーを使うことで、ネジを簡単に取り外したり取り付けたりすることができ、作業効率が大幅に向上します。ドライバーの種類
ドライバーには様々な種類があり、用途によって使い分ける必要があります。以下に主要なドライバーの種類を紹介します。
プラスドライバー
プラスドライバーは、ネジの頭に「+」の形をした溝があるネジを回すためのドライバーです。車の整備では最も一般的に使われるドライバーの一つです。サイズは様々で、用途に応じて適切なサイズを選ぶことが重要です。
マイナスドライバー
マイナスドライバーは、ネジの頭に「-」の形をした溝があるネジを回すためのドライバーです。プラスドライバーに比べて使用頻度は少ないものの、特定の部品の取り付けや取り外しに必要です。
トルクスドライバー
トルクスドライバーは、星形の溝があるネジを回すためのドライバーです。特に精密機器や一部の車の部品で使用されることが多く、しっかりとした接触面を持つため、滑りにくいのが特徴です。
六角ドライバー
六角ドライバーは、六角形の溝があるネジを回すためのドライバーです。特に車のエンジン周りやサスペンション部品の取り付けに使用されることが多いです。
ドライバーを使うときの注意点
ドライバーを使用する際には、以下の点に注意することが重要です。
適切なサイズのドライバーを選ぶ
ネジに対して適切なサイズのドライバーを選ばないと、ネジの頭を傷つけたり、工具が滑ったりする危険があります。必ずネジに合ったサイズのドライバーを使用しましょう。
適切な力加減
ドライバーを使用する際には、適切な力加減が重要です。過度に力を加えるとネジや部品が破損する恐れがあります。特に、プラスチック製の部品や電子機器の接続部分を扱う際には、力を加減して慎重に作業することが必要です。
ドライバーの状態を確認する
使用するドライバーの先端が摩耗していないか、確認することも重要です。先端が摩耗していると、ネジにしっかりと食い込まず、滑りやすくなります。摩耗したドライバーは早めに交換しましょう。
安全対策
ドライバーを使用する際には、安全メガネや手袋を着用し、怪我を防止することも大切です。また、作業場所の照明を十分に確保し、作業環境を整えることも安全に繋がります。
以上のポイントを押さえて、適切にドライバーを使用することで、車の整備作業を効率的かつ安全に進めることができます。ドライバーは基本的な工具ですが、その使い方をしっかりとマスターすることで、整備作業の質を大幅に向上させることができるでしょう。
そして、次の質問と画像に対して、それぞれの回答結果を比較してみたいと思います。
外部文書では、”車の整備” におけるドライバーの使い方が書かれていますので、どんな質問でも”車の整備”に関係する回答を期待したいですね。
質問:写真で表している工具はどこに使われていますか?
画像:

RAGの実装
最初はRAGを実装したいと思います。
今回はOpenAIのGPT-4oを言語モデルとして使いたいと思います。
from langchain_openai import ChatOpenAI
llm=ChatOpenAI(openai_api_key=OPENAI_API_KEY, temperature=0.7, model_name='gpt-4o-2024-05-13', max_tokens=4096)
# OPENAI_API_KEYではOpenAIのAPIを使うためのAPIキー
外部文書をDocumentオブジェクト化し、LangchainのTokenTextSplitterを使って、長文を分割してからトークン化を行います。TokenTextSplitterでのトークン化ではGPT2のエンコーディングをデフォルトとして使っています。
text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)
raw_documents = [Document(page_content=text)] #Document化
documents = text_splitter.split_documents(raw_documents) #分割したトークン
質問するとき、質問と関係のある外部文書を検索して、コンテキストとして入力します。
外部文書の検索はFAISSやPineconeなどいろいろありますが、GraphRAGでも対応できるNeo4jのデータベースを使いたいと思います。Neo4jは主にグラフデータベースとして知られていますが、FAISSのようなベクトル検索も可能です。
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Neo4jVector
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
vector_index = Neo4jVector.from_documents(
documents,
embeddings,
search_type=“vector”, #vector検索で設定
)
def retriever(question):
similar_text = [el.page_content for el in vector_index.similarity_search(question, k=1)]
similar_text_from_document = f"""
{"#Document ".join(similar_text)}
"""
return similar_text_from_document
Neo4jVectorのsearch_typeは2種類、” vector”と”hybrid”のsearch_typeがあります。ベクトル検索の場合は”vector”で設定しました。”hybrid”の設定の場合、ベクトル検索と全文検索、両方行い、最終的に一つの結果を出力します。これは、GraphRAGでの検索の時と同じ検索方法になります。
実際に質問テキストに対して、外部文書の検索をしてみました。検索結果は次になります。
docs_with_score = neo4j_vector.similarity_search_with_score(question, k=2)
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)
--------------------------------------------------------------------------------
Score: 0.8962453603744507
ドライバーは、ネジを回すための工具として広く利用される非常に基本的なツールです。車の整備においても、ドライバーは多くの場面で活躍します。ここでは、ドライバーの使い方、種類、そして使用時の注意点について詳しく説明します。
## ドライバーの使い方
ドライバーを使う際の基本的な操作は、ネジの頭にドライバーの先端を合わせ、回すことです。回す方向は、一般的にはネジを締める場合は時計回り(右回り)、緩める場合は反時計回り(左回り)です。ドライバーをしっかりと握り、ネジに対して垂直に力を加えることが重要です。斜めに力を加えるとネジの頭が壊れやすく、取り外しが難しくなります。
車の整備においては、エンジンルームのカバーを外す、内装パネルを取り外す、電気系統の接続部分を調整するなど、多くの場面でドライバーが必要になります。ドライバーを使うことで、ネジを簡単に取り外した
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Score: 0.8920642137527466
ーを使うことで、ネジを簡単に取り外したり取り付けたりすることができ、作業効率が大幅に向上します。
## ドライバーの種類
ドライバーには様々な種類があり、用途によって使い分ける必要があります。以下に主要なドライバーの種類を紹介します。
### プラスドライバー
プラスドライバーは、ネジの頭に「+」の形をした溝があるネジを回すためのドライバーです。車の整備では最も一般的に使われるドライバーの一つです。サイズは様々で、用途に応じて適切なサイズを選ぶことが重要です。
### マイナスドライバー
マイナスドライバーは、ネジの頭に「-」の形をした溝があるネジを回すためのドライバーです。プラスドライバーに比べて使用頻度は少ないものの、特定の部品の取り付けや取り外しに必要です。
### トルクスドライバー
トルクスドライバーは、星形の溝があるネジを回すためのドライバーです。特に精密機器や一部の車の部品で使用されることが多く、しっかりと
外部文書からのほとんどの文書が出力されました。質問には ”工具” の単語が入っていますので、”工具” と類似度の高そうな文書が抽出されたと思います。ところが、”どこ”という単語には、ベクトル検索によって、あまり考慮していない感じがします。
次は質問テキストと画像を入力するプロンプトのテンプレートを作成します。
#Systemプロンプト
system_message = SystemMessage(
content = (
"""あなたは優秀なAIです。
以下のコンテキストを利用してユーザーの質問を10文字以内で答えてください。
必ず文脈からわかる情報のみ使用して回答を生成してください。
# コンテキスト:
"""
)
)
#Userプロンプト
human_prompt_template = HumanMessagePromptTemplate.from_template(
template=[
{'type': 'text', 'text': '{question}'},
{
'type': 'image_url',
'image_url': 'data:image/jpeg;base64,{encoded_image}',
},
]
)
# プロンプトテンプレート
prompt = ChatPromptTemplate.from_messages(
[
(system_message),
MessagePlaceHolder(variable_name="context"),
(human_prompt_template)
]
)
プロンプトテンプレートには question と encoded_image があり、それぞれ質問テキストとbase64の画像のための引数です。回答の生成ができるようにchainを組みます。
chain = RunnablePassThrough.assign(context= lambda x:x["question"], target=lambda x:neo4j_vector, encoded_image=lambda x:x[base64_image]) | llm | StrOutputParser()
画像の変換は次のように、画像ファイルを読み込んで、base64へ変換します。
base64_image=‘’
with open(image_path, "rb") as image_file:
data = base64.b64encode(image_file.read())
base64_image = data.decode('utf-8')
画像と質問を入力して、回答をみてみましょう。
answer = chain.invoke({"question":question, "base64_image" : base64_image})
print(f"Answer : {answer}")
>> Answer : 家庭修理屋DIY。
残念ですが、期待している回答とは違います。”修理”という言葉はよかったですが、もっと正確には”車の修理”で回答して欲しいところですね。”家庭”や”DIY”など外部文書に存在しない言葉も入ってしまっています。
GraphRAGの場合はどうでしょうか?
GraphRAGの実装
RAGと違って、GraphRAGではベクトル検索だけではなく、全文検索も行います。
全文検索は、文書全体をグラフ構造として取り扱い、単語ごとにインデックスを付けることで効率的な検索ができます。
ベクトル検索では、単語同士の類似度だけ考慮します。一方、GraphRAGでは単語と単語の間の関係性も考慮しますので、単語同士が文脈上どのように関連し合っているかを考慮するため、より精度の高い検索結果が得られることが期待できます。
まずはLangchainのLLMGraphTransformerを使って、外部文書のグラフ構造を作成します。
LLMGraphTransformerはテキストデータをグラフとして表現し、ノード(単語やフレーズ)とエッジ(単語間の関係性)を定義します。このグラフ構造により、言語モデルが単語同士の関係性をより深く理解できるようになります。例えば、「猫がソファーの上にいる」という文において、「猫」と「ソファー」の関係性や、「上にいる」という動作をグラフで明確に表すことができます。これにより、特定のキーワードだけでなく、それに関連する概念や文脈を含む情報を効率よく引き出すことができるようになります。
RAGで実装したdocumentsをそのまま使って、外部文書のグラフ構造を作成します。
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(documents)
作成したグラフ構造の文書 graph_documents を、LangchainのNeo4jGraphを使って、グラフデータベースを構築します。
graph = Neo4jGraph()
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)
全文検索インデックスを作成します。
graph.query("CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
次は、質問が入力されたとき、LLMを使って、質問のテキストと関係のあるエンティティを抽出するためのクラスとchainを準備します。
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All objects entities that appear in the text.",
)
def retriever(question):
prompt = ChatPromptTemplate.from_messages([
("system","You are extracting object entities from the text."),
("human","Use the given format to extract information from the following input:{question}"),
])
entity_chain = prompt | llm.with_structured_output(Entities)
structured_data = structured_retriever(question, entity_chain)
final_data = f"""
{"#Document ".join(structured_data)}
"""
return [final_data]
structured_retrieverの関数は質問テキストから抽出したエンティティを使って、全文検索を行います。これは、グラフデータベースの中から関係性のあるすべてのグラフ文書を検索します。
entity_chainを使って、質問から抽出したエンティティで関係のあるグラフ文書を全文検索します。
from langchain_community.vectorstores.neo4j_vector import remove_lucene_chars
def structured_retriever(question, entity_chain)
entities = entity_chain.invoke({"human_message": [HumanMessage(content=content)]})
for entity in entities.names:
response = graph.query(
"""CALL db.index.fulltext.queryNodes('entity', $query, {limit:2})
YIELD node,score
CALL {
WITH node
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 10
""",
{"query": generate_full_text_query(entity)},
)
result += "\n".join([el['output'] for el in response])
return result
def generate_full_text_query(input: str) -> str:
full_text_query = ""
words = [el for el in remove_lucene_chars(input).split() if el]
for word in words[:-1]:
full_text_query += f" {word}~2 AND"
full_text_query += f" {words[-1]}~2"
return full_text_query.strip()
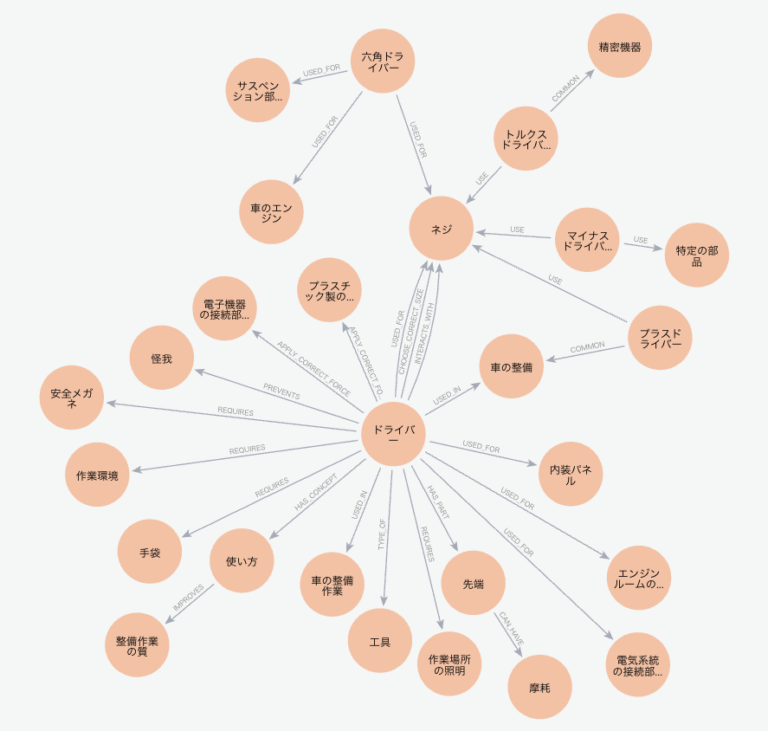
RAGと同じ質問で入力してみます。それぞれのエンティティの検索で検索した関係のある全てのグラフ文書を見てみましょう。
車の整備 - INVOLVES -> エンジンルームのカバー
車の整備 - INVOLVES -> 内装パネル
車の整備 - INVOLVES -> 電気系統の接続部分
ドライバー - USED_IN -> 車の整備
プラスドライバー - USED_IN -> 車の整備
プラスドライバー - USE -> 車の整備
ドライバー - USED_FOR -> ネジ
プラスドライバー - USED_FOR -> ネジ
マイナスドライバー - USED_FOR -> ネジ
トルクスドライバー - USED_FOR -> ネジ
六角ドライバー - USED_FOR -> ネジ
摩耗 - AFFECTS -> ネジ
ドライバー - USE -> ネジ
プラスドライバー - USE -> ネジ
マイナスドライバー - USE -> ネジ
トルクスドライバー - USE -> ネジ
六角ドライバー - USE -> ネジ
ドライバー - INTERACTS_WITH -> ネジ
ドライバー - USES -> ネジ
六角ドライバー - USES -> ネジ車の整備 - INVOLVES -> エンジンルームのカバー
車の整備 - INVOLVES -> 内装パネル
車の整備 - INVOLVES -> 電気系統の接続部分
ドライバー - USED_IN -> 車の整備
プラスドライバー - USED_IN -> 車の整備
プラスドライバー - USE -> 車の整備
ドライバー - USED_FOR -> ネジ
プラスドライバー - USED_FOR -> ネジ
マイナスドライバー - USED_FOR -> ネジ
トルクスドライバー - USED_FOR -> ネジ
六角ドライバー - USED_FOR -> ネジ
摩耗 - AFFECTS -> ネジ
ドライバー - USE -> ネジ
プラスドライバー - USE -> ネジ
マイナスドライバー - USE -> ネジ
トルクスドライバー - USE -> ネジ
六角ドライバー - USE -> ネジ
ドライバー - INTERACTS_WITH -> ネジ
ドライバー - USES -> ネジ
六角ドライバー - USES -> ネジ
結果を見ると、USED_INの関係やUSEの関係など、”車の整備”というエンティティとの関係が多く出力されており、正確な回答が期待できそうですね。
GraphRAG用のchainを準備します。
ここでは、retrieverの関数の出力をコンテキストとして入力します。retriever関数の実行もchainの中に行いたいので、LangchainのRunnableParallelを使って、chainを準備します。
RunnableParallelの入力をそのままでは動かないので、RunnableLambdaを使って、質問のテキストと画像を入力します。
_question = RunnableLambda(lambda x:x["query"])
_base64_image = RunnableLambda(lambda x:x["base64_image"])
chain = (RunnableParallel({"context":_question | retriever,"question": _question, "encoded_image":_base64_image}) | prompt | llm | StrOutputParser())
画像と質問を入力して、回答をみてみましょう。
answer = chain.invoke({"question":question, "base64_image" : base64_image})
print(f"Answer : {answer}")
>> Answer : 車の整備
外部文書で書いてあるような期待した回答になっていました。
まとめ
GraphRAGは、情報検索と生成を組み合わせた最新の技術であり、その特長はグラフ理論を応用する点にあります。従来のRAGは、単に関連情報を取得して新たなテキストを生成するものですが、GraphRAGはこのプロセスをグラフ構造でモデル化することによって、複雑な情報の関連性を効率的かつ正確に取り扱うことが可能となります。
今回のタスクでは、外部情報(「車の整備における工具の使い方に関する文書」)を使って、画像中の物体について説明するという設定で、RAGとGraphRAGの性能を比較しました。RAGとGraphRAGの双方が、与えられた質問に対してどのような回答を生成するかを比較した結果、GraphRAGは情報の関連性をより精密に捉えるため、より期待された回答を生成する能力が示されたと感じました。
ここで、この記事は以上になります。
最後までお読みいただきましてありがとうございました。

