
GMOグローバルサイン・ホールディングスCTO室のZulfazli@zulfazlihussinです。
私はhakaru.aiの開発チームにてAI開発を担当しております。今回は、マルチモーダル対応のモデルを使って、事前学習が必要としない画像分類器の実装について述べます。
マルチモーダル学習
マルチモーダル学習(Multimodal Learning)は、異なる種類の情報を統合する機械学習のアプローチです。このアプローチは、テキスト、画像、音声など、異なるモーダルからの情報を結合することで、複数の情報源から複合的に判断することができるようになります。例えば、映画の感情分析を考えてみましょう。テキストレビューだけでなく、映画の画像や音声などからの情報を統合することで、より正確な分析や予測が可能になると思います。
Transformerでマルチモーダル
Transfomerはもともと自然言語タスクの向けに設計されましたが、その柔軟性から、画像、音声、テキストなどの異なるモーダル情報を結合して学習することができます。TransformerはAttentionのメカニズムを採用しており、2つの入力情報に対して、各要素とどの程度関係しているのか計算するために使用されます。2つの入力情報源が同一の場合、Self-Attentionと呼び、異なる場合はCross-Attentionと呼びます。マルチモーダルの場合、2つの異なる情報源が入力することになりますので、Cross-Attentionのようなメカニズムを使います。Transformerについての記事「Transformerをゼロから実装する」も書きましたので、よければ読んでみてください。
CLIPについて
CLIP (Contrastive Language-Image Pre-training)[1]は2021年にOpenAIが開発した画像とテキストを組み合わせたマルチモーダル学習です。CLIPでは図1で表していますようにAttentionのようなメカニズムを使って、画像とテキストを入力することで、関連性の高い画像ーテキストのペアが特定できるようなマルチモーダル学習です。これにより、視覚的な特徴とセマンティックな特徴を関連付けることができるようになります。例えば、画像に対して単語や文章の意味、関連性、文脈などを表すテキストを関連付けることで、情報検索や文書分類、質問応答などの自然言語処理タスクにおいて、データの意味的な特徴を理解・解釈することができます。この幅広い応用と性能から注目を集めており、、今後のAIの発展に寄与することが期待されています。
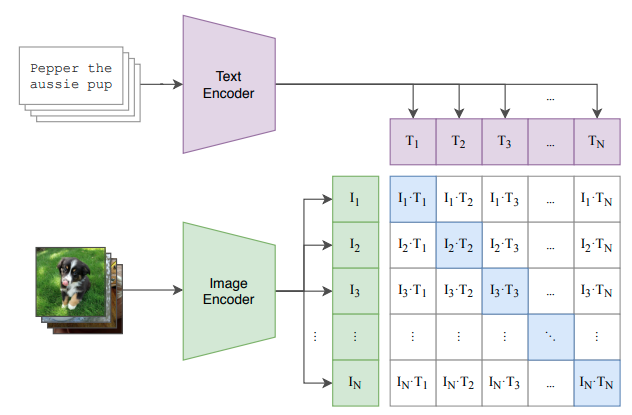
CLIP モデルの学習環境
今回は、OpenCLIPを参考にして、メーターの画像とそのメーターを説明するテキスト(メーターの種類についてやメーターの登録方法についてなど)のセットの情報を使って学習しました。OpenCLIPはCLIPをベースに構築され、オープンソースバージョンプロジェクトとして提供しています。学習環境の詳細は下記通りです。
| 項目 | 値 |
|---|---|
| GPU | NVIDIA H100 |
| Pythonバージョン | 3.10.6 |
| Pretrainedモデル | RN50 |
| データセット数 | 93万 |
図2 では今回のマルチモーダル学習での損失関数の値を表しています。
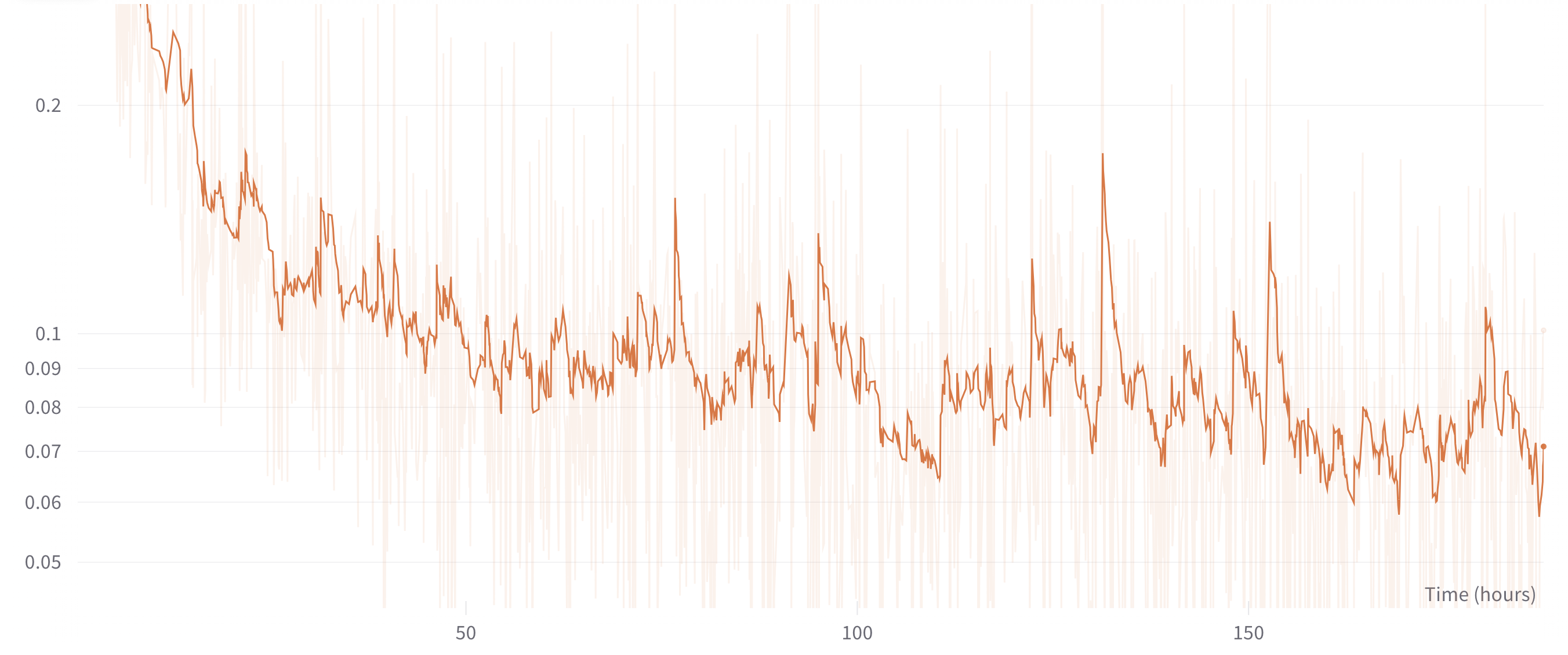
図2: 学習のときの損失
Zero-shotの画像分類を実装する
学習したCLIPのマルチモーダルを使って、zero-shotの画像分類を実装したいと思います。少ない画像で学習する方法、few-shot学習(前編、後編)についての記事も以前書いたことがありました。few-shot学習とzero-shot学習は両方とも、モデルが新たなタスクやドメインに対して、膨大なデータを再学習する負担を減らすことができる学習方法ですが、今回のzero-shot学習の概念は少し違います。
通常の画像分類では、新しいラベルに基づいて分類したいとき、そのラベルに基づいたラベリング作業が必要になり、再学習をしてからそのラベルに基づいた分類を行いましたが、zero-shotでは新しいラベルに対して事前学習が行われず、画像分類が可能になります。そのため、新たな分類タスクが必要な場合でも柔軟に対応できるAIモデルを実現することが可能になります。
今回は、学習したCLIP モデルを使って、メーターの画像を入力して、次の3つのメータータイプを分類したいと思います。分類するとき、下記のラベルを新しく設定し、再学習することなく、分類したいと思います。
1.デジタルメーター(7セグ)
2.回転式メーター
3.アナログメーター丸型
まずは、ラベルの文字列を数値化します。CLIPモデルを学習したときに使っているpretrainモデルはRN50(ResNet-50)のモデルですので、文字列を数値化するときにも同じようにRN50のtokenizerを使っています。
tokenizer = open_clip.get_tokenizer('RN50')
input_text = ["デジタルメーター(7セグ)","回転式メーター","アナログメーター丸型"]
input_text_batch = tokenizer(input_text)
次は、推論したい画像を学習したマルチモーダルのCLIPモデルを読み込みます。
device = "cuda" if torch.cuda.is_available() else "cpu"
im = preprocess_image(image_path,(224,224))
input_image_batch = preprocess_val(im).unsqueeze(0).to(device)
model, _ , preprocess = open_clip.create_model_and_transforms('RN50','folder/model.pt')
データの前処理を行うpreprocessは以下のようになっています。
preprocess
Compose(
Resize(size=224, interpolation=bicubic, max_size=None, antialias=warn)
CenterCrop(size=(224, 224))
<function _convert_to_rgb at 0x7fc2fde35940>
ToTensor()
Normalize(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711))
)
実際に画像データを使って、新しいラベルで画像を分類しましょう。今回は3枚のメーター画像で分類したいと思います。下記は、1枚のメーター画像を分類するときの処理になります。
image_path = "clip/inference/images/meter_1.jpg"
img = Image.open(image_path)
img = preprocess_val(img).unsqueeze(0).to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(input_image_batch)
text_features = model.encode_text(input_text_batch)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
text_probsは3つのラベルのテキストそれぞれに対して、入力する画像との類似度はどれぐらいあるのかという確率になります。確率が高ければ、そのラベルのテキストとの類似度が高いということです。text_probsはどんな出力になるか見てみましょう。
print("text_probs : {}"".format(text_probs))
text_probs : tensor([[0.6141, 0.3113, 0.0746]])
入力した3枚のメーター画像の結果は以下の通りになります。



2.回転式メーター : 0.3113
3.アナログメーター丸型 : 0.0746
2.回転式メーター : 0.9950
3.アナログメーター丸型 : 0.0009
2.回転式メーター : 0.0001
3.アナログメーター丸型 : 0.9997
上記の結果を見ますと、入力したメーター画像に対して、メーターの種類が正しく分類されていることが分かるかと思います。
まとめ
マルチモーダル学習(画像⇆テキスト)によって、新しいラベルに対する再学習をせず、メーター画像のメーター種類を分類することができました。画像からテキストを出力することができるため、LLMを使い、画像とチャットできるようなアプリもできると思います。今後、挑戦してみたいと思います。
終わり
ここで、この記事は以上になります。
最後までお読みいただきましてありがとうございました。

