はじめに:音声に注目した理由
今日は植松です。2025年の初め頃から、音声AIに強い関心を持ち始めました。
「2025年末には、ウェブサイトへの音声AI導入が当たり前になるだろう」——そう予感していたのですが、結果的にその予測は外れてしまいました。ただ、方向性としては間違っていなかったのではないかと思っています。
AIチャットがウェブサイトに広まり、商品説明や問い合わせ対応をAIが行うボットも珍しくなくなりました。でもふと思うんですよね——テキストで質問して、テキストで答えを読むって、本当に便利なのかな、と。
知りたいことがあるとき、「話して、聞く」のが自然じゃないでしょうか。キーボードを打って文章を読むより、声で聞いて耳で受け取る方がずっと楽なはずです。だから、TTS(テキスト読み上げ)とSTT(音声認識)の技術がいずれ広まるだろうな、と感じていました。
もう一つ、気になっていたことがあります。
Chromeにはページ全体を読み上げる機能がありますが、ページ全体を読み上げてほしいわけじゃないですよね。知りたいのは「このページ、何が書いてあるの?」という要約だけだと思うんです。30秒から1分で概要を把握して、興味があれば読む——それで十分なはずです。
特にブログ記事は長くなりがちで、冒頭に1分程度の音声要約があれば、読者がまず聴いて判断できるのではないかと思いました。Googleはすでに英語のコンテンツでこれを実現しています。では日本語では? 中国語では? それをWordPressで簡単にできるようにしたい——それがQuikVox AI開発の出発点でした。
3つのTTSを使い比べた
音声コンテンツの実装を検討する中で、現在主流のTTSサービスをいくつか実際に使い比べてみました。試したのは OpenAI TTS・ElevenLabs・Google Gemini TTS の3つです。
それぞれに明確な個性があって、「どれが最高か」は一言では言えないな、というのが正直な感想です。目的によって選ぶべきサービスが変わってくると思っています。
OpenAI TTS:速さと着実な進化
生成速度が速く、APIとしての安定性も高い印象でした。バージョンを重ねるごとに品質が上がっていて、日本語の発音精度も実用水準に達していると感じています。
ただマルチスピーカーには非対応で、複数話者のコンテンツを作ろうとすると、声ごとに個別生成して手動で結合するしかありません。感情表現はやや平坦な印象で、情報伝達には向いていますが、物語性のあるコンテンツには少し物足りなさを感じました。
ElevenLabs:「生身の人間」に最も近い
3つの中で最も人間の声に近いと感じたのがElevenLabsです。音声タグ機能でテキスト中に抑揚や間を細かく指定でき、生成された音声を聴いたとき、思わず「本当に人が話しているのでは」と感じるほどのリアリティがありました。
特に印象的だったのが安定性です。AI音声は同じボイス・同じテキストでも生成のたびに微妙にブレるものなのですが、ElevenLabsはそのブレが極めて小さく感じました。長文をチャンク分割して生成してもつなぎ目の違和感が少なく、生成速度もGeminiより速い印象で、体感で約2倍くらい違うように思います。マルチスピーカーは3人以上にも対応しています。
Gemini TTS:ドラマの俳優、シーンを読む
Geminiをひと言で表すなら「ドラマや映画の声優」という感じです。
人間の日常会話よりも感情表現が強めで、「えっ、本当ですか!?」という驚きを、私たちは普段そこまで大げさには表現しませんよね。でもドラマや映画では感情を明確に表現する——Gemini TTSはそのスタイルに近いと思います。私たちがテレビ・映画に長年慣れているせいか、この「ドラマ的表現」が自然に聞こえるんですよね。
特に驚いたのはシーン理解の精度です。テキストの文脈を読み取って、悲しい場面では悲しい話し方を、緊張感のある場面では緊張を帯びた声色を自動で選んでくれます。テキストを「読む」のではなく、コンテンツを「理解して演じる」感覚があって、これはすごいなと思いました。
弱点としては、音質のブレが大きいことがあります。長文をチャンク分割すると、チャンク間で声のトーンが離れてしまうことがあって、そこは少し使いづらさを感じています。
比較表
| OpenAI | ElevenLabs | Gemini | |
|---|---|---|---|
| 生成速度 | ◎ | ◎ | ○ |
| 人間らしさ | ○ | ◎ | △ |
| 感情表現 | △ | ○ | ◎ |
| シーン理解 | △ | ○ | ◎ |
| 音質の安定性 | ○ | ◎ | △ |
| チャンク一貫性 | ○ | ◎ | △ |
| マルチスピーカー | ✗ | ◎(3人以上) | ○(2人まで) |
| コスト | ○ | △ | ◎ |
目的別の選び方(個人的な感覚として)
- リアリティ・安定したブランドボイス → ElevenLabs
- ウェブ・ブログの集客・没入感 → Gemini
- 情報読み上げ・速度重視 → OpenAI
自分で試せる比較ツールを作った
3つのサービスを説明するより、実際に聴き比べてもらうのが一番早いと思っています。そこで、OpenAI・ElevenLabs・Geminiを同時に音声生成できる比較ツールをHTMLで作りました。
まずは実際の聴き比べをどうぞ。
ツールのUIはこのようになっています。
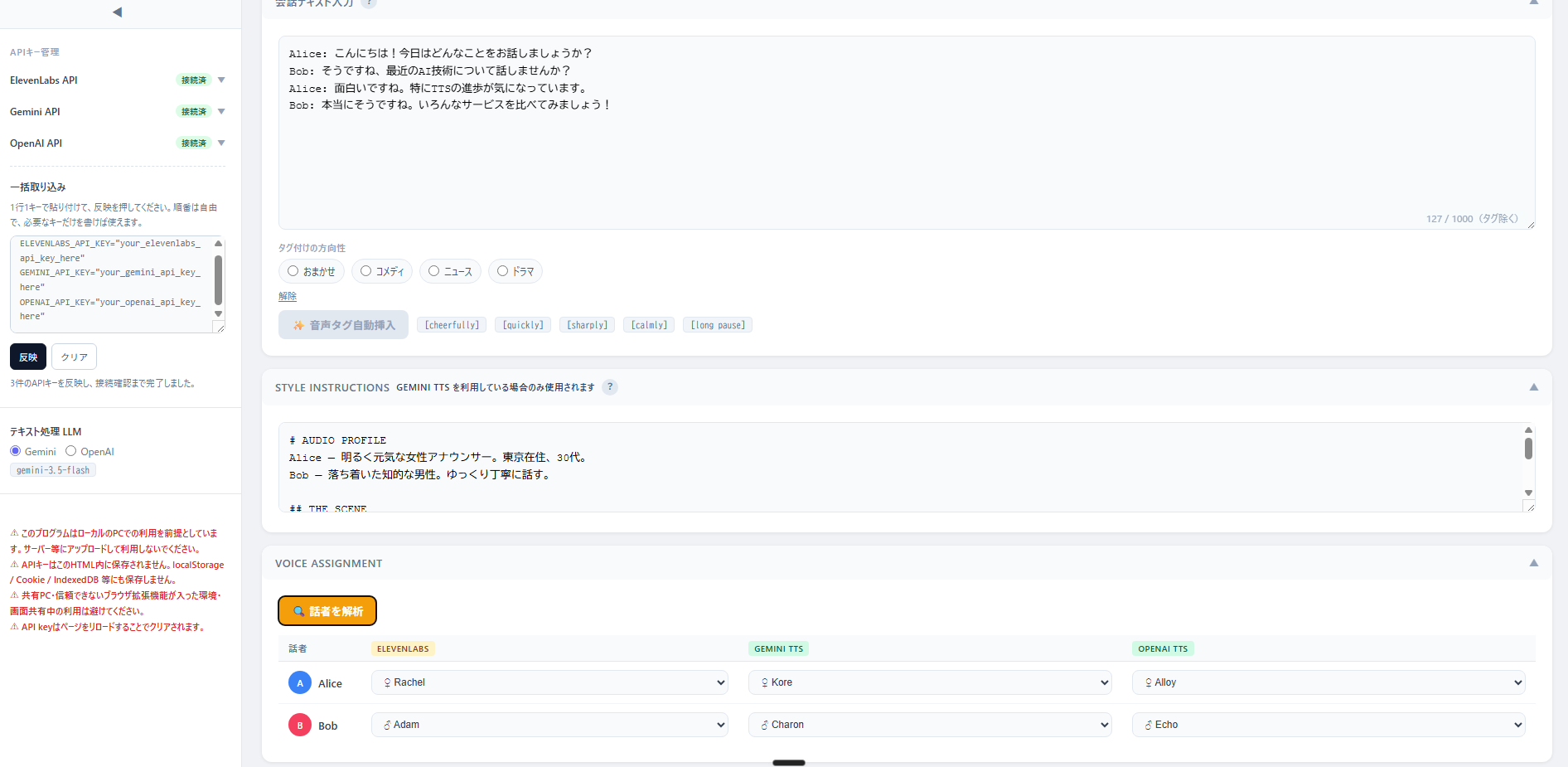
APIキーを貼り付けて「反映」を押すだけで、ElevenLabs・Gemini・OpenAIの3サービスに同時接続できます。テキストを入力して生成すれば、速度の差・声質の違い・感情表現の豊かさが一度に確認できます。マルチスピーカーにも対応しており、話者ごとにボイスを割り当てられるので、2人の掛け合いを3サービスで聴き比べることもできます。
→ 比較ツールをダウンロード(.txtファイル)
https://quikvox-ai.com/downloads/index.txt
ファイルを .html に名前変更してブラウザで開くだけで使えます。
なぜ.txtで配布しているのか
HTMLをウェブ上でそのまま動かすと、XSS(クロスサイトスクリプティング)に悪用されるリスクがあります。また、サーバー上でAPIキーを扱う構成にしてしまうと、第三者のキーが漏洩する危険もあります。ローカルで動かす形にすることで、API通信はすべてユーザー自身の環境から直接行われ、キーが外部に渡りません。
Gemini TTSの感情表現:漫才で証明する
百読は一聴にしかず。Geminiの感情表現とシーン理解がどこまで来ているか、この音声をぜひ聴いてみてください。
Gemini TTSのマルチスピーカーで生成した漫才です。 ネタはちゃんと作りました。2人のキャラクターの掛け合い、ボケとツッコミのテンポ、感情の抑揚——掛け合いとして成立していると思っています。AIが「演じる」時代が来ているんだなと感じた瞬間でした。
チャンク処理の仕組み:長文音声生成の裏側
Gemini TTS で長文を音声生成するとき、テキストをそのまま1回のAPIリクエストで送ることはできません。チャンク(chunk) と呼ばれる単位に分割して、複数のAPIリクエストに分けて処理します。
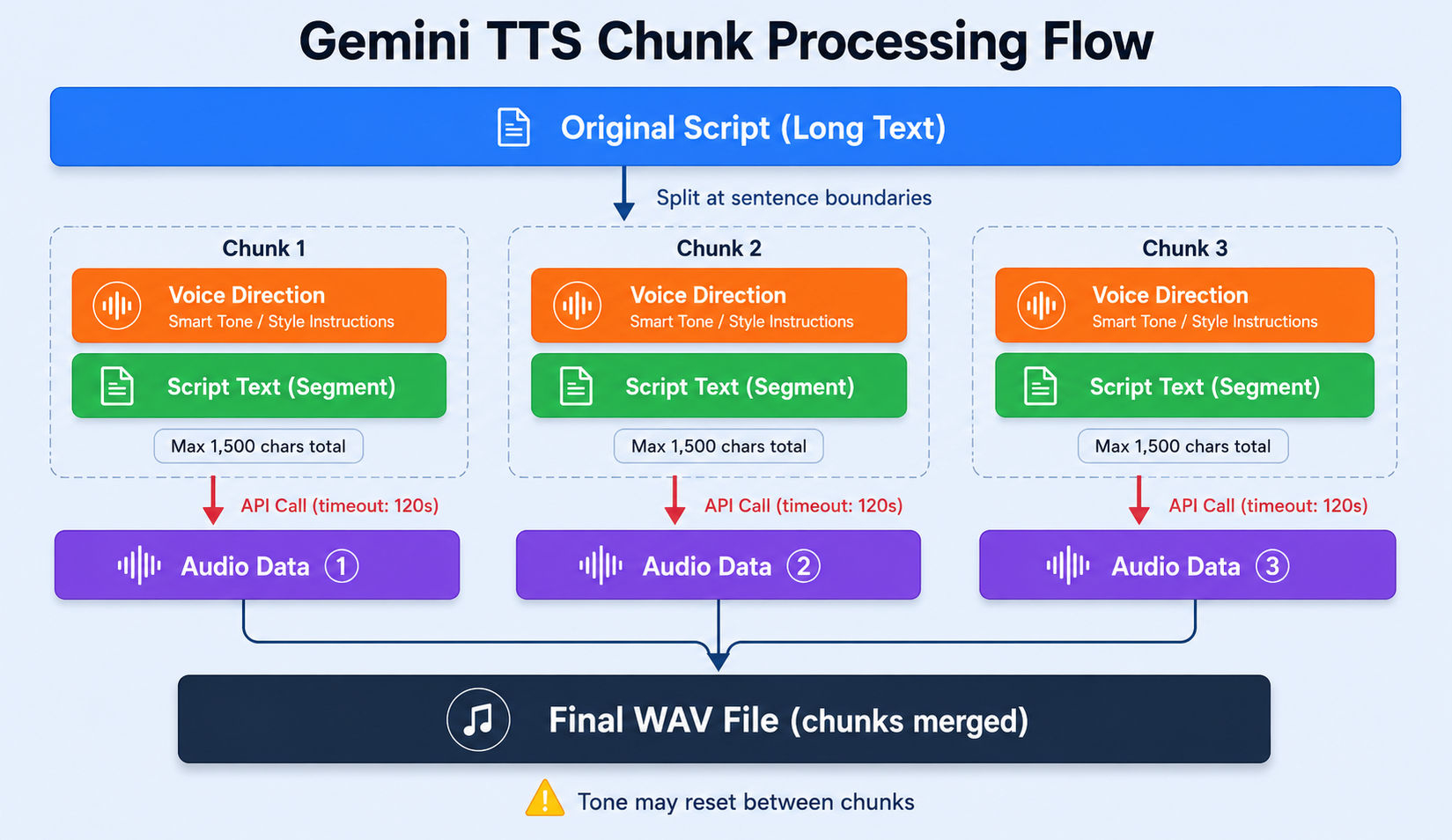
なぜチャンク分割が必要なのか
Gemini TTS APIには以下の制約があります。
| 項目 | 制限値 |
|---|---|
| 1リクエストあたりのテキスト | 最大4,000バイト(テキスト)+ 4,000バイト(プロンプト)= 計8,000バイト |
| APIタイムアウト | 1リクエストあたり120秒 |
| 出力音声の最大長 | 約655秒 |
特にタイムアウトの問題が大きく、長文を1回のリクエストで処理しようとすると途中でタイムアウトが発生してしまいます。QuikVox AIでは安全マージンを取り、1チャンクあたり最大1,500文字(Voice Directionを含む全プロンプト合計)に制限しています。
Voice Directionとは何か
各チャンクには、テキスト本文だけでなくVoice Direction(音声スタイル指示)が毎回含まれます。QuikVox AIでは「Smart Tone」と呼んでいる機能です。
Voice Direction:
{音声スタイルの指示(感情・トーン・話し方など)}
TTS the following script in a single voice:
{テキスト本文}このVoice Directionがあることで、Geminiは「どんな感情で読むか」「どんなシーンの音声か」を理解します。チャンク処理では毎回この指示を送り直すため、Voice Directionのサイズが大きいほど、1チャンクに入る本文テキストが少なくなります。
チャンク間のトーン揺れ問題
図の下部に「Tone may reset between chunks」と書いた通り、チャンク間でGeminiの解釈が微妙にズレることがあります。同じVoice Directionを毎回送っていても、チャンクの区切りで声のトーンが若干変わってしまうのです。
これはGemini TTSの現状の課題で、ElevenLabsと比べると顕著な差として感じます。ElevenLabsはチャンク分割後も声のトーンが一貫していて、つなぎ目の違和感がほとんどありません。
WordPressに組み込む:スクリプトと音声タグの本質
比較ツールを作っていて気づいたことがあります。
TTSのAPIを叩くこと自体は、それほど難しくありません。難しいのは「何を音声にするか」と「どう読ませるか」だと思っています。
ブログ記事をそのままAPIに投げても、良い音声にはならないんですよね。記事はあくまで「読む文章」として書かれていて、「聴く文章」とは構造が違います。句読点の位置、話の展開、強調すべき箇所——それをポッドキャスト向けに再構成する必要があります。さらにGemini TTSの表現力を活かすには、どこで感情を強調するか、どこで間を置くかを音声タグで指示することが大事で、そこにはノウハウが要ります。
このスクリプト構成と音声タグの設計、つまり「テンプレート」と「プロンプト設計」こそが、音声コンテンツの品質を左右するのではないかと感じています。
それをWordPressの管理画面から、記事ごとにワンクリックで実行できるようにしたいと思い、個人で開発したのが QuikVox AIです。
WordPressプラグインとしてWordPress.orgで公開しています。Google Gemini APIキーがあれば、無料で試していただけます。
まとめ
ドラえもん、C3PO、AIBO——僕たちはずっと、AIに感情を求めてきたような気がします。笑ってほしい、悲しんでほしい、一緒に喜んでほしい。それはSFの夢だったはずなんですよね。
今回、音声生成AIで漫才を作ってみて、そんなことを改めて感じました。AIはもう「情報を届けるツール」ではないのかもしれない。喜怒哀楽を演じ、人の心を動かせる存在になりつつあるのではないかと思っています。
これは音声だけの話ではなく、AI音楽も同じ変化の中にあるような気がしています。「処理するAI」から「感動を与えるAI」へ——そんな転換点に、今いるのかもしれないと感じています。