GMOグローバルサイン・ホールディングス CTO室 所属の宗形(@S_muna112)です。Stable Diffusion、ComfyUI、Trellis2を統合し、プロンプトから高品質な3Dアセットを自動出力する統合ワークフローを構築しました。本ツールのこだわりは、ComfyUIの複雑なノード構成をエンドユーザー(非エンジニア)が直接触れずに済むようGradioでラップし、誰でも手軽に扱える操作感に落とし込んだ点にあります。
1. はじめに:1時間程度で「使える3D」が手に入る
本稿では、パイプラインの設計思想とコンポーネント構成、そして実運用における最適化のポイントを紹介します。3Dモデリングおよび画像生成AIの経験者であれば、本システムがもたらすワークフローの効率化を即座に理解いただけるはずです。
「光沢のある青い龍、複雑な装飾」——。 このプロンプトを入力してから、テクスチャ付きのGLBファイルが完成するまでわずか1時間程度。
通常、これほど複雑なモデルをゼロから手作業でモデリングし、テクスチャリングまで完結させるには、熟練の技術者でも数日から、場合によっては数週間の工数を要します。本パイプラインは、その膨大な制作時間をわずか60分前後にまで凝縮。DCCツール(Blender等)へ即座に投入可能なアセット制作において、従来の常識を覆す圧倒的なスピードアップを実現しました
ここがポイント:
高価なサーバークラスタは不要です。一般的な RTX 4070 (12GB VRAM) 搭載のPC一台で、画像生成から3D化までを完結できるよう設計されています。
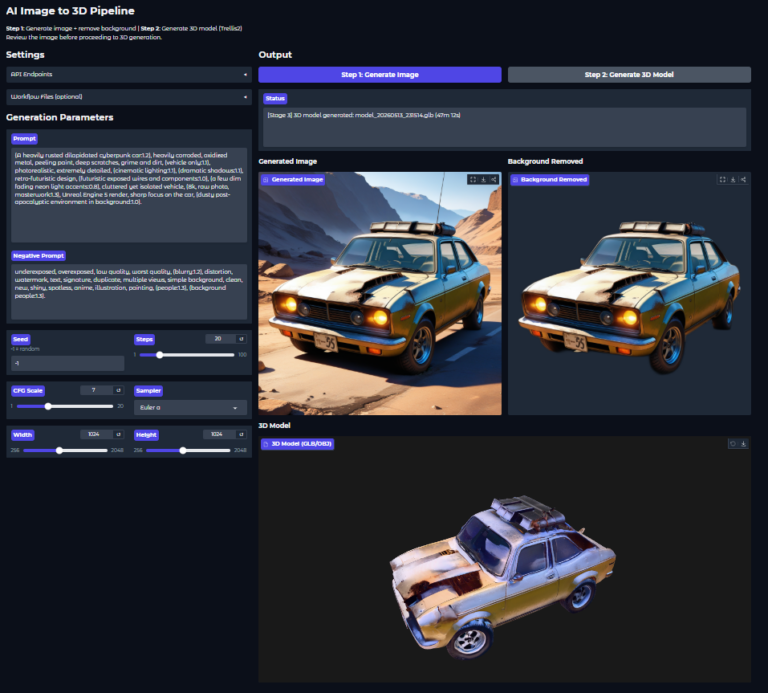
2. パイプラインの全体像:3つのステージ
処理は大きく分けて3つのステージを、REST APIを介してリレー形式で進みます。
- Stage 1: Stable Diffusion (txt2img)
- プロンプトからベースとなる2D画像を生成(数秒〜数十秒)
- Stage 2: rembg (背景除去)
- 画像をRGBA変換し、3D化に必要な「抜き」を作成(5〜10秒)
- Stage 3: Trellis2 (3D生成)
- 2D画像から3Dメッシュを再構成し、4096pxのテクスチャを焼き込み(30〜80分)
システム構成の裏側
フロントエンドには Gradio を採用し、バックエンドでは SD WebUI (Port: 7861) と ComfyUI (Port: 8188) をヘッドレスモードで並列稼働させています。メインの制御プログラム(app.py)がこれらをREST APIで操る仕組みです。
3. コンポーネント別の役割
3-1. 画像生成(Stable Diffusion / A1111)
APIエンドポイントを通じて画像を生成します。設定(stepsやcfg_scale等)は config.py で一括管理可能です。重要なのは、Stage 1終了後に VRAMを明示的にアンロード することで、後続のTrellis2にリソースを全開放する点にあります。
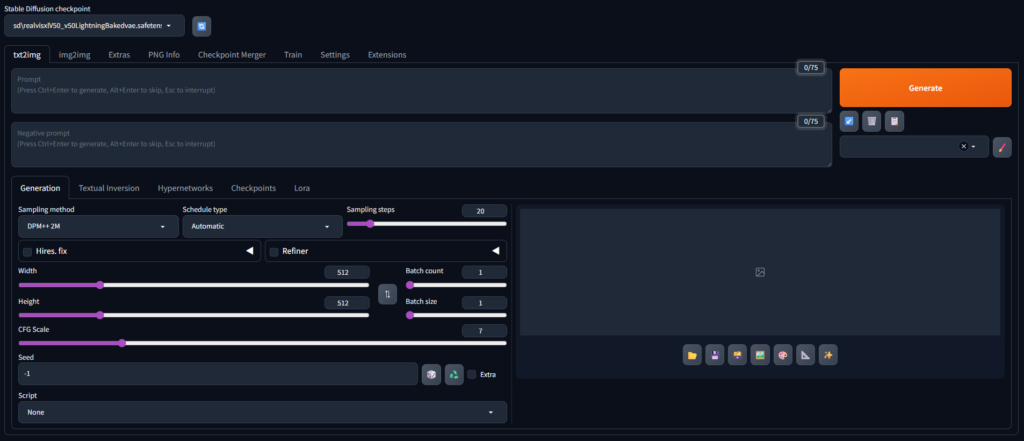
3-2. 背景除去(rembg)
ONNX Runtimeベースで動作する背景除去ライブラリです。この工程では、Stable Diffusionで生成した2D画像を、3D再構成に適した「透過情報付き画像」へ変換します。
主な特徴とメリット
・RGBA PNGによる透過情報の維持
出力はAlphaチャンネル付きPNGとして生成され、透明領域情報を保持したまま後続の3D再構成処理へ受け渡せます。
・CPU実行によるVRAM節約
CPU版ONNX Runtimeを利用することで、背景除去処理時のGPUメモリ消費を抑えられます。
・GPUワークロードとの分離
背景除去をCPU側へオフロードすることで、Stable DiffusionなどGPU負荷の高い処理とのVRAM競合を回避しやすくなります。
3-3. 3D生成の核心(Trellis2)
本プロジェクトの心臓部。最大の特徴は、FP8量子化版(TRELLIS.2-4B-FP8) の採用です。
- FP32(通常版): 約16GB以上のVRAMが必要。
- FP8(量子化版): 約4GBまでメモリ使用量を圧縮。これにより、12GB VRAMのRTX 4070環境でも、実用的な品質を維持したまま動作が可能になりました。
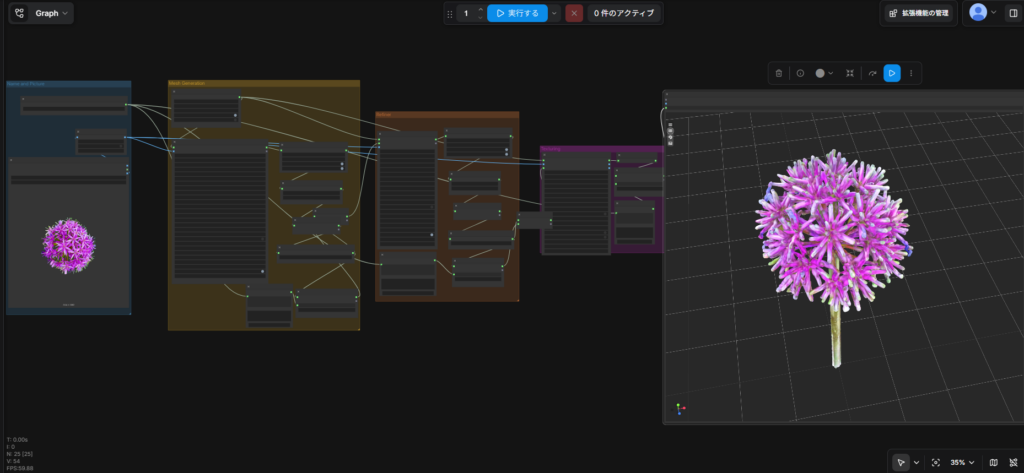
本パイプラインの核心であるComfyUI上のTrellis2ワークフローは、以下のような緻密なノード構成で構築されています。
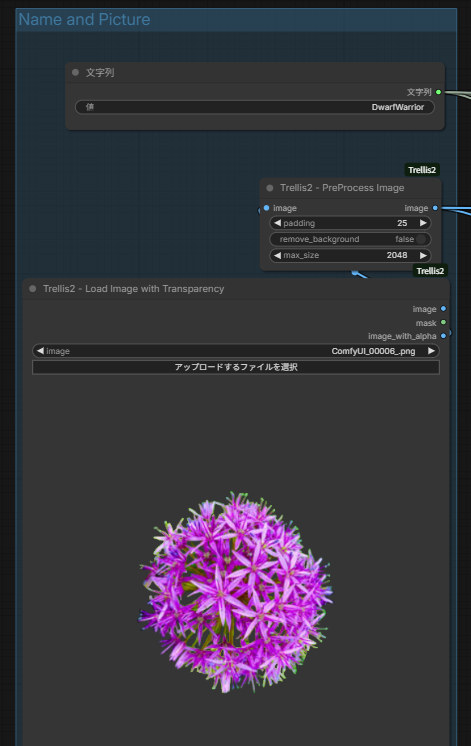
1. 入力と前処理(Input & Pre-processing)
まずはベースとなる画像を読み込み、3D生成に適した形に整えます。
- 使用ノード:
LoadImage→PreProcess
2. コア生成(AdvancedGenerator)
本パイプラインの心臓部であり、最も計算リソースを消費する工程です。
- 使用ノード:
AdvancedGenerator - ポイント: 全体の処理時間の50〜75%を占める最大のボトルネックとなります。ここでの潜在空間生成が最終的な形状の質を決定します。
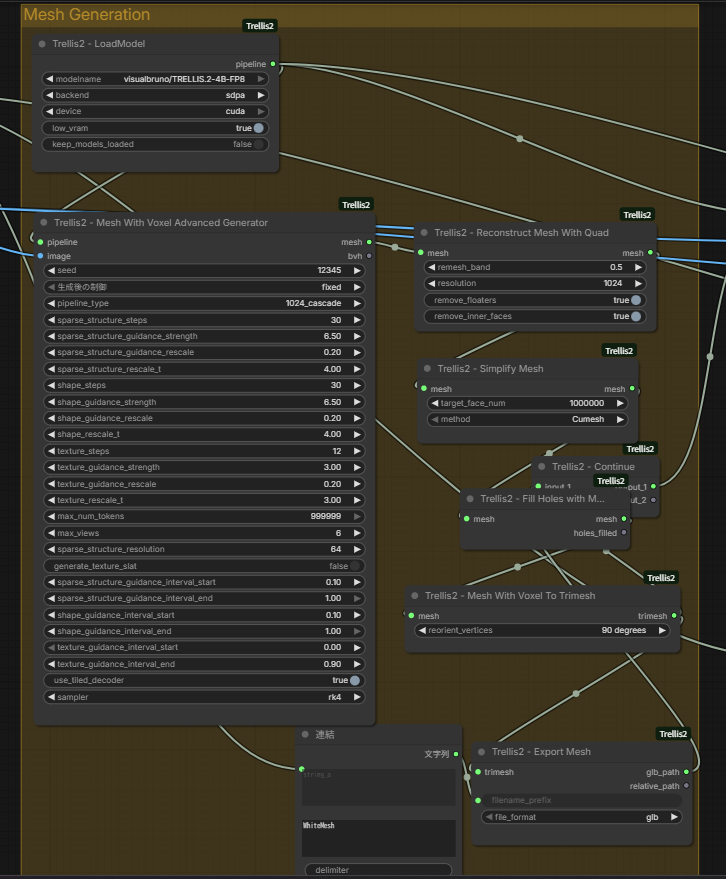
3. メッシュの基本構築(Basic Mesh Construction)
生成されたデータから、立体的なメッシュ構造を組み立てます。
- 使用ノード:
ReconstructMesh→SimplifyMesh(軽量化) →FillHoles(穴埋め) →ToTrimesh - ポイント: ここで一度、形状のみの「ホワイトメッシュ」が形成されます。
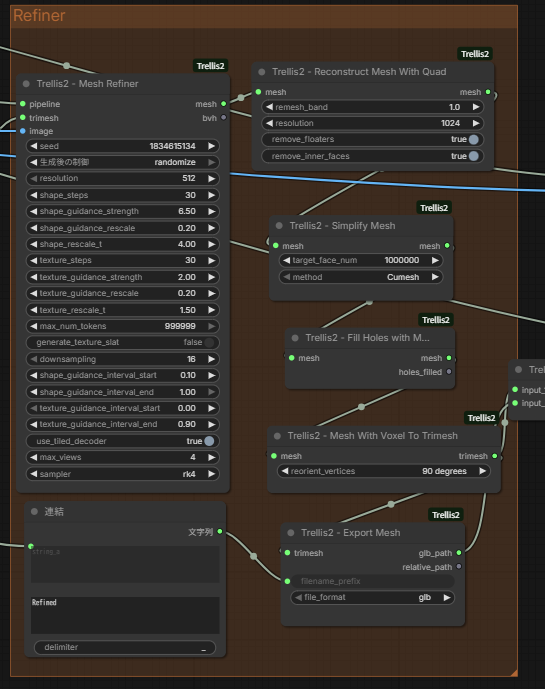
4. ディテールのリファイン(Detail Refinement)
粗いメッシュを磨き上げ、細部の精度を高めます。
- 使用ノード:
MeshRefinerを中心とした再構成フロー - ポイント:
MeshRefinerを通じて、より高精細なメッシュへとブラッシュアップされます。
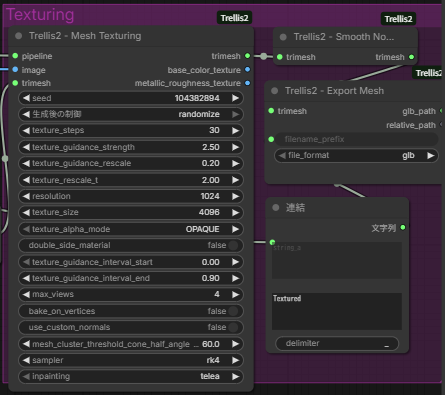
5. テクスチャリングと書き出し(Texturing & Export)
最終的な仕上げとして、色と質感を設定しファイルを出力します。
- 使用ノード:
MeshTexturing→SmoothNormals→ExportMesh - ポイント:
MeshTexturingでは4096pxの高解像度でテクスチャが生成されます。最終的に GLB形式 で出力され、Blender等ですぐに利用可能になります。
4. 処理時間とGPU別ベンチマーク
ボトルネックは主に AdvancedGenerator(潜在空間生成)にあります。お手持ちの環境での目安を確認してください。
※RTX 4070は個人による実測値です。他GPUは参考推定値であり、環境・プロンプト複雑度により大きく変動します。
| 搭載GPU | 想定処理時間 |
| RTX 4090 | 20〜30分 |
| RTX 4070 Ti | 30〜50分 |
| RTX 4070 (推奨) | 40〜80分 |
| RTX 4060 Ti | 90〜120分 |
| RTX 3060 | 120〜180分 |
※ テクスチャ解像度を4096pxから2048pxへ変更することで、全体の時間を 10〜15%短縮 できます。
5. 実用ノウハウ:なぜ「2ステップ操作」なのか?
本ツールはあえて完全自動化せず、画像生成後に「確認ステップ」を挟んでいます。
- 時間のロスを防ぐ: Stage 3には最長80分かかります。低品質な画像で無駄な時間を過ごさないよう、2D段階で選別を行います。
- VRAMの動的管理: 次のコード(
utils.pyより)のように、ステージ間で強制的にメモリをクリアすることで、単一GPUでの安定動作を支えています。
Python
# Stage 1完了後のVRAMクリア(utils.pyより抜粋)
def release_vram(target="all"):
if target in ("all", "sd_webui"):
requests.post("http://127.0.0.1:7861/sdapi/v1/memory",
json={"unload_models": True}) # SDモデルのアンロード
import torch
if torch.cuda.is_available():
torch.cuda.empty_cache() # キャッシュクリア
torch.cuda.synchronize()
6. セットアップとプロンプトのコツ
起動方法
Stability Matrix環境で、ディレクトリ移動後に start.bat を叩くだけで、依存パッケージのインストールからGradioの立ち上げまで自動で行われます。
3D化に強いプロンプト
「単色背景」「スタジオ照明」「正面〜斜め45度」を意識してください。
例: 「青の龍、透きとおった翼、複雑な鱗、スタジオ照明、ホワイト背景、高品質」
7. まとめと将来性
FP8量子化と緻密なVRAM管理により、ついに 「手元のPC」でend-to-endの3D生成 が現実のものとなりました。
現在はTrellis2固定ですが、構成はモジュール化されているため、将来的に他の3D生成モデルへの差し替えも容易です。ゲームアセットのラフ起こしやコンセプトアートの立体確認など、クリエイティブの上流工程を劇的に変える可能性を秘めています。
最後に、本記事はあくまで概念実証(PoC)としてのアーキテクチャ紹介です。 今後の技術発展により、さらに最適化されたワークフローが登場することを期待しています。