GMOグローバルサイン・ホールディングスCTO室の@zulfazlihussinです。
私はhakaru.aiの開発チームにてAI開発を担当しております。今回は、Variational AutoEncoder(VAE)を実装し、画像の異常箇所の除去に使ってみたいと思います。
AutoEncoder
AutoEncoderはEncoder(エンコーダ)とDecoder(デコーダ)の2つの部分から構成されています。エンコーダは入力データを高次元空間から低次元空間(潜在空間)に圧縮し、データの重要な特性を抽出します。デコーダは、圧縮された潜在空間の情報を使って、データを再び高次元空間に再構築します。潜在空間は入力されたデータから生成されるため、デコーダの出力も入力データにできるだけ近いものとなります。
PCAとは何が違う?
潜在空間はデータの主成分分析(PCA)で得られる固有空間に非常に似ています。PCAの主成分は、データ空間内での線形な結合で表現されます。PCAは、高次元空間の相関行列の固有値を分解し、寄与率の高い固有ベクトルを使って低次元空間を作成します。これは、AutoEncoderの潜在空間と同様にデータの重要な特性を捉えます。
では、なぜAutoEncoderを使うのでしょうか?
AutoEncoderは、PCAと異なり、非線形変換を用いて高次元空間から低次元空間へとデータを変換します。AutoEncoderは、活性化関数や多くの隠れ層を追加することで、情報損失を大幅に減らすことができます。
Variational AutoEncoder(VAE)
AutoEncoderの潜在空間は、入力データがどのように表現されているかが明確ではありません。しかし、Variational AutoEncoder (VAE)[1] では、各入力に対して潜在空間内の分布のパラメータを出力します。その後、この潜在分布が正規分布になるような制約を設けています。誤差逆伝播法を用いて、これらの分布を学習することが可能です。これにより、学習した分布を使って入力データに似た新しいデータを生成することができるようになります。
VAEで画像の異常箇所を除去する
今回は、VAEを使ってMVTecのデータを学習し、異常がある画像を検出してみたいと思います。
Encoder
Variational Autoencoder (VAE)のエンコーダ部分を実装したいと思います。Encoderは、入力画像を圧縮して潜在空間へ変換する役割を持っています。また、潜在空間の平均と標準偏差を学習し、それをサンプリングして潜在ベクトルとして利用します。
まずはサンプリング層を実装します。この層は、VAEに特有な部分で、潜在空間の分布から潜在ベクトルをサンプリングします。具体的には、平均 (z_mean) と標準偏差の対数 (z_log_var) から潜在ベクトル z を生成します。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
from PIL import Image
class Sampling(layers.Layer):
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
潜在空間の次元数 (latent_dim) と入力画像のサイズ (input_shape) を定義します。
latent_dim = 10
input_shape = (image_size, image_size, 3)
Encoderの部分を実装します。Encoderでは画像データを入力して、入力データの潜在空間へ変換します。潜在空間の平均と分散を学習し、そこから潜在ベクトルをサンプリングします。
# encoder model
inputs = Input(shape=input_shape, name='encoder_input')
x = Conv2D(32, (3, 3), activation='relu', strides=2, padding='same')(inputs)
x = Conv2D(64, (3, 3), activation='relu', strides=2, padding='same')(x)
x = Flatten()(x)
z_mean = Dense(latent_dim, name='z_mean')(x)
shape = x.shape
z_log_var = Dense(latent_dim, name="z_log_var")(x)
z = Sampling()([z_mean, z_log_var])
encoder = Model(encoder_inputs, [z_mean, z_log_var, z], name="encoder")
Decoder
DecoderではVAEの潜在空間からサンプリングされたベクトルを入力とし、畳み込み層と全結合層を使用して、元の高次元画像データを生成します。このようにして、Encoderで抽出された潜在表現を基に、元のデータを再構築することができます。
# decoder model
latent_inputs = Input(shape=(latent_dim,), name='z_sampling')
x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs)
x = Reshape((shape[1], shape[2], shape[3]))(x)
x = Conv2DTranspose(64, (3, 3), activation='relu', strides=2, padding='same')(x)
x = Conv2DTranspose(32, (3, 3), activation='relu', strides=2, padding='same')(x)
outputs = Conv2DTranspose(3, (3, 3), activation='sigmoid', padding='same')(x)
decoder = Model(latent_inputs, outputs, name='decoder')
outputs = decoder(encoder(inputs))
VAE モデル
VAEの学習を行うためのカスタムモデルクラスを定義しています。このクラスは、EncoderとDecoderのモデルを組み合わせて、VAE全体として機能するものです。再構築損失とKL Divergence 損失[2]を計算し、モデルの重みを更新します。
class VAE(keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.total_loss_tracker = keras.metrics.Mean(name="total_loss")
self.reconstruction_loss_tracker = keras.metrics.Mean(name="reconstruction_loss")
self.kl_loss_tracker = keras.metrics.Mean(name="kl_loss")
@property
def metrics(self):
return [
self.total_loss_tracker,
self.reconstruction_loss_tracker,
self.kl_loss_tracker,
]
def predict(self, x):
z_mean, _, _ = self.encoder.predict(x)
y = self.decoder.predict(z_mean)
return y
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
keras.losses.binary_crossentropy(data, reconstruction), axis=(1, 2)
)
)
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}
MVTecデータセットを読み込み、前処理を行った後、VAEモデルを学習を行います。
def get_mvtec_data():
x = ['train_img_path1','train_img_path2',...]
y = ['test_img_path1','test_img_path2',...]
x_train_path , x_test_path , _ , _ = train_test_split(x,y, test_size = 0.33, random_state=42)
x_train = np.empty([len(x_train_path),size,size,3])
x_test = np.empty([len(x_test_path),size,size,3])
for idx, train_img in enumerate(x_train_path):
x_train[idx]=np.asarray(Image.open(train_img[0]).convert('RGB').resize([size,size]))
for idx, test_img in enumerate(x_test):
x_test[idx]=np.asarray(Image.open(test_img[0]).convert('RGB').resize([size,size]))
return x_train, x_test
x_train, x_test = get_mvtec_data()
image_size = x_train.shape[1]
original_dim = image_size * image_size
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), size, size, 3))
x_test = np.reshape(x_test, (len(x_test), size, size, 3))
batch_size = 128
epochs = 2000
vae = VAE(encoder, decoder)
vae.compile(optimizer=keras.optimizers.Adam())
history = vae.fit(mnist_digits, epochs=epochs, batch_size=batch_size)
結果
ここでは、上記の学習したVAEモデルを使って、実際の異常がある画像を利用して、正常画像の再構成ができているかどうか比較してみました。左の画像がVAEの入力画像、右の列が出力画像を示しています。出力画像では画像の異常箇所(例えば、錠剤の斑点やカプセルの汚れ、線維の破損など)が除去されています。これはVAEが正常な画像パターンを学習し、異常を除去し、再構成していることがわかるかと思います。




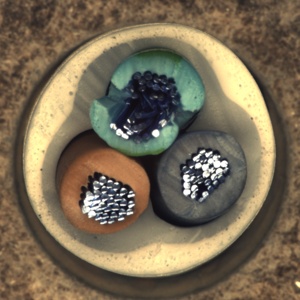
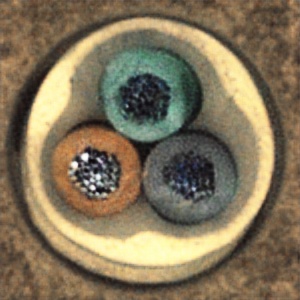
まとめ
VAEが入力画像と出力画像の違いを基に異常箇所を特定・除去することができました。
VAEは正常なパターンを効果的に学習し、異常箇所を除去する形で画像生成能力があることが確認されました。
今回の記事は以上です。
最後までお読みいただきましてありがとうございました。
参考
[1] Diederik P Kingma, Max Welling; Auto-Encoding Variational Bayes, arXiv:1312.6114; December 2022[2] Kullback-Leibler Divergence Explained