
こんにちは。CTO室長の浅野@masakz5です。
今までSSI/VCモデルについては、神沼から主に実装サイドからアプローチした記事を掲載していました。
今回は私の方から、SSIの考え方が出現した背景や標準化についての様々な団体の活動、またSSIの現在地について解説していきたいと思います。
自己主権型アイデンティティ(Self Sovereign Identity – SSI)登場の背景
インターネットの世界の中での“Identity”の扱いについては長らく議論がされており、様々に形を変えながら実装がされてきました。
Christopher Allen氏は2016年のThe Path to Self-Sovereign Identityというブログポストの中で、ネットの中の“Identity”は以下のような変遷を辿ってきたと記しています。
フェーズ1:中央主権型(Centralized) Identity
電子認証局やドメインレジストラ、あるいは個々のサイトによってIdentityが中央集権的にコントロールされる形態。インターネットの世界が広がるに従ってIdentityのコントローラは増殖し、1人のユーザのIdentityがサイト毎に分散するようになる。
フェーズ2:連邦型(Federated)Identity
異なるID基盤を相互連携させる形態で、Identityの分散の問題を解決し、1つのIDを複数のサービスで使用できるようにすることを目的とする。ただし、依然としてそれぞれのIDはそれぞれの基盤で管理される。
フェーズ3:ユーザー中心型(User-Centric)Identity
Identityの管理をユーザ自身が行い、それを使用して様々なサービスを使用できるようにすることを目的する。OpenIDやOpenID Connect, OAuth, FIDOなどを仕様として策定したが、技術的な制約から実装上IDの登録や管理を特定のサービスサイトやプラットフォーマーに依存することが多くなり、結果的にIdentity管理が中央集権的になる。
フェーズ4:自己主権型(Self-Sovereign)Identity
ユーザ自身が完全にIdentityの管理(コントロール)を行う。ユーザが自身のIdentityの「支配者」になる。
上記のように、Identityの管理方法は(インターネット上の他のテクノロジーと同様に)形態を変えながら集中と分散を繰り返してきました。ただ、フェーズ3までは結果的に持ち主以外の第3者にIdentity(及び付帯する属性等の情報)の管理を任せる形になっており、Identityと付帯する情報の「主権者」であるべき持ち主が完全にそれらをコントロールできない状態でした。その要因の一つとして、テクノロジー的な制約によってこれらの情報を管理するコストが高くなってしまい、個人が管理することが現実的ではなかった、ということが考えられます。
自己主権型(Self-Sovereign)Identity(SSI)では主権者であるIdentityの持ち主がこれらの情報を完全にコントロールできるようになることを目指しています。分散台帳技術の出現等によって、個人レベルにまで分散してIdentityを管理するためのコストが下がったことも、SSIを進める原動力の1つになっていると思われます。
以降では、W3CでのSSI関連の標準化について簡単にご紹介し、続いてその周辺で行われている各団体の動きについてご紹介します。
SSI/DIDの基本的な概念
DID
SSIの世界で中心となるのが、まずDIDと呼ばれるIDの持ち主(Subjectと呼ばれる。個人やモノ、法人など)の識別子です。
W3CによるDIDの定義は以下のとおりです。
A globally unique identifier that does not require a centralized registration authority because it is registered with distributed ledger technology or other form of decentralized network.
(分散台帳あるいはその他の非中央集権ネットワークに登録されるため中央集権的な登録機関を必要としない、グローバルに一意な識別子。)
DIDは以下の形式をとります。
did:example:123456789abcdefghi
上記のように、DIDはコロンで区切られた3つのパートから成り立っています。
1つ目のパート(“did”)は固定値で、これがDIDであることを表しています。
2つ目のパート(“example”)はメソッド名を表しています。
メソッド内で定義されたIDメソッドというのはDIDが格納される分散台帳ネットワークの実装方式に紐付いて定義された名称です。
以下はW3Cで定義されたメソッドの一例です。
| Method Name | DLT or Network | Authors |
|---|---|---|
| did:erc725: | Ethereum | Markus Sabadello, Fabian Vogelsteller, Peter Kolarov |
| did:example: | DID Specification | W3C Credentials Community Group |
| did:ipid: | IPFS | TranSendX |
| did:sov: | Sovrin | Mike Lodder |
| did:uport: | Ethereum | uPort |
| did:ethr: | Ethereum | uPort |
| did:ion: | Bitcoin | Various DIF contributors |
| did:jolo: | Ethereum | Jolocom |
3つ目のパート(“123456789abcdefghi”)は各メソッド内で定義された、メソッド内でユニークな識別子です。
DID Document
上記のDIDに対し、DIDの持ち主(サブジェクト)について述べたデータのセットをDID Documentといいます。DID Documentには、サブジェクトが自身の認証およびDIDとの紐付けを証明するために使用できる、公開鍵や匿名化された生体データ等のメカニズムを含みます。また、後述するVCを取得するポイントなどをサービスエンドポイントとして示すことができます。
W3CによるDID Documentの定義は以下のとおりです。
A set of data that describes the subject of a DID, including mechanisms, such as public keys and pseudonymous biometrics, that the DID subject can use to authenticate itself and prove their association with the DID.
(DIDの主体(サブジェクト)について述べたデータのセットであり、DIDサブジェクトが自身の認証およびDIDとの紐付けを証明するために使用できる、公開鍵や匿名化された生体データ等のメカニズムを含む。)
以下が最小単位のDIDドキュメントのサンプルです。
{
"@context": "https://www.w3.org/2019/did/v1",
"id": "did:example:123456789abcdefghi",
"authentication": [{
// used to authenticate as did:...fghi
"id": "did:example:123456789abcdefghi#keys-1",
"type": "RsaVerificationKey2018",
"controller": "did:example:123456789abcdefghi",
"publicKeyPem": "-----BEGIN PUBLIC KEY...END PUBLIC KEY-----\r\n"
}],
"service": [{
// used to retrieve Verifiable Credentials associated with the DID
"id":"did:example:123456789abcdefghi#vcs",
"type": "VerifiableCredentialService",
"serviceEndpoint": "https://example.com/vc/"
}]
}
“Id”で修飾されている項目がDIDです。”authentication”の項目は、認証方法を表しています。このサンプルの場合、RSA鍵の検証を行うことで認証を行います。実際の公開鍵が”publicKeyPem”に記されています。
“service”という項目には、このサブジェクトに関連する情報を取得するためのサービスのエンドポイントが記載されます。
ここでは、後に解説するVerifiable Credentialの取得場所を記載しています。
PII(個人識別情報)の取り扱いについて
DID及びDID DocumentにおけるPII(個人識別情報)について、W3Cでは以下のように定義しています。
If a DID method specification is written for a public DID Registry where all DIDs and DID Documents will be publicly available, it is STRONGLY RECOMMENDED that DID Documents contain no PII. (中略)
This also enables subjects and relying parties to implement the GDPR right to be forgotten, as no PII will be written to an immutable ledger.
(もしDIDメソッドの仕様が、全てのDIDやDID Documentを誰もが入手可能になるようなパブリックなDIDレジストリのために書かれるのだとしたら、DIDドキュメントにはPIIを含めないことを強く推奨します。 (中略)
これによって、PIIが変更不可能な台帳に書かれることがなくなり、サブジェクトと信頼者がGDPRの「忘れられる権利」を実装することが可能になります。)
つまり、DID及びDID Documentがいわゆるパブリックなブロックチェーンのような、誰でもアクセス可能な場所に格納されるのであれば、その中にPIIを含めるべきではない、ということです。
Verifiable CredentialとClaims
W3Cの定義によると、Claimとは、発行者によるDIDの持ち主(Subject/Holder)に関する「表明」であり、主にサブジェクトの属性情報等を表します。同じ発行者(Issuer)から発行された1つあるいは複数のClaimのセットをCredentialといい、耐タンパ性を持ち、発行者を暗号的に検証可能な状態であるCredentialをVerifiable Credentialといいます。
Verifiable Credentialは以下のように、Credentialの種類や発行者、発行日等が記載されたMetadata、Claim、そして電子署名データ等のProofから構成されます。
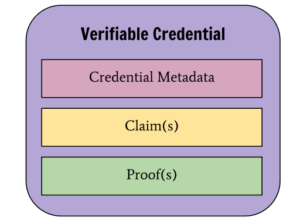
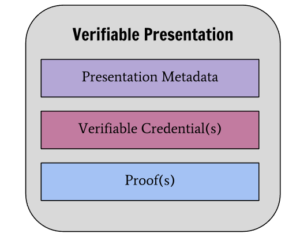
また、状況により複数のCredential(あるいはClaim)を検証者(Verifier)に提示する必要がある場合には、Verifiable Presentationとしてまとめて提示することが可能です。この場合内包され得るそれぞれのVerifiable Credentialについては発行者が異なっていても問題ありません。
以下は卒業証明書のVerifiable Credentialの例です。
{
// set the context, which establishes the special terms we will be using
// such as 'issuer' and 'alumniOf'.
"@context": [
"https://www.w3.org/2018/credentials/v1",
"https://www.w3.org/2018/credentials/examples/v1"
],
// specify the identifier for the credential
"id": "http://example.edu/credentials/1872",
// the credential types, which declare what data to expect in the credential
"type": ["VerifiableCredential", "AlumniCredential"],
// the entity that issued the credential
"issuer": "https://example.edu/issuers/565049",
// when the credential was issued
"issuanceDate": "2010-01-01T19:73:24Z",
// claims about the subjects of the credential
"credentialSubject": {
// identifier for the only subject of the credential
"id": "did:example:ebfeb1f712ebc6f1c276e12ec21",
// assertion about the only subject of the credential
"alumniOf": {
"id": "did:example:c276e12ec21ebfeb1f712ebc6f1",
"name": [{
"value": "Example University",
"lang": "en"
}, {
"value": "Exemple d'Université",
"lang": "fr"
}]
}
},
// digital proof that makes the credential tamper-evident
// see the NOTE at end of this section for more detail
"proof": {
// the cryptographic signature suite that was used to generate the signature
"type": "RsaSignature2018",
// the date the signature was created
"created": "2017-06-18T21:19:10Z",
// purpose of this proof
"proofPurpose": "assertionMethod",
// the identifier of the public key that can verify the signature
"verificationMethod": "https://example.edu/issuers/keys/1",
// the digital signature value
"jws": "eyJhbGciOiJSUzI1NiIsImI2NCI6ZmFsc2UsImNyaXQiOlsiYjY0Il19..TCYt5X
sITJX1CxPCT8yAV-TVkIEq_PbChOMqsLfRoPsnsgw5WEuts01mq-pQy7UJiN5mgRxD-WUc
X16dUEMGlv50aqzpqh4Qktb3rk-BuQy72IFLOqV0G_zS245-kronKb78cPN25DGlcTwLtj
PAYuNzVBAh4vGHSrQyHUdBBPM"
}
上記では、発行者の情報(issuer)、サブジェクト(あるいはHolderと呼ばれます)の情報(Subject)、Credentialの種類が卒業証明書であること(alumniOf)、学校名の英語とフランス語の表記、そしてProofの情報とJSON Web Signature(JWS)形式の電子署名が記載されていることがわかります。
標準化と実装に向けた動き
標準化団体
現在様々な団体が様々な観点からSSIの標準化あるいは実装に向けた活動を行なっています。ここでは、その中のいくつかの団体についてその活動内容をご紹介します。
W3C
W3C(World Wide Web Consortium)では、主にDIDやVerifiable Credentialのアーキテクチャやデータモデル、ユースケース等を検討、ドキュメント化しています。DIDの検討はDIDワーキンググループ、Verifiable Credential関連の検討はVerifiable Credentials Working Groupで行われています。
DIF
DIF(Decentralized Identity Foundation)は、非中央集権型アイデンティティ(Decentralized Identity)のエコシステムの構築に必要となるエレメントの開発を目的とした団体で、さまざまなワーキンググループでその検討が行われています。具体的にはDIDそのもののやり取りの方法やDIDを使用した認証の方法、クレデンシャルの実装、データの保管方法などが議論されています。
Sovrin Foundation
Sovrin FoundationはSSIをインターネット上で実現するための”Sovrin Network”の実装を目的として2016年に結成された非営利団体です。様々なツールやライブラリ等がオープンソースで開発されていますが、その中の分散台帳に関する部分のソースコードがLinux Foundation配下でブロックチェインを専門に行っているHyperledgerプロジェクトに寄付され、Hyperledger Indyの基礎となりました。
ERC725
ERC725はブロックチェーン上でSSIの実現と管理を行うために提案されたEthereumの標準規格案で、ERC20およびWeb3.jsの作成者であるFabian Vogelsteller氏によって提案されました。
当初提案されたERC725は、2018年10月にERC725-v2とERC734の2つの規格案に分割され、最新の企画案はプロキシアカウントの規格であるERC725-v2、鍵管理の規格であるERC734、クレームホルダーの規格ERC735の3つから構成されています。
DIFによる標準化の例
ここでは、DIFが検討しているSSIの実装の全体像をご紹介します。
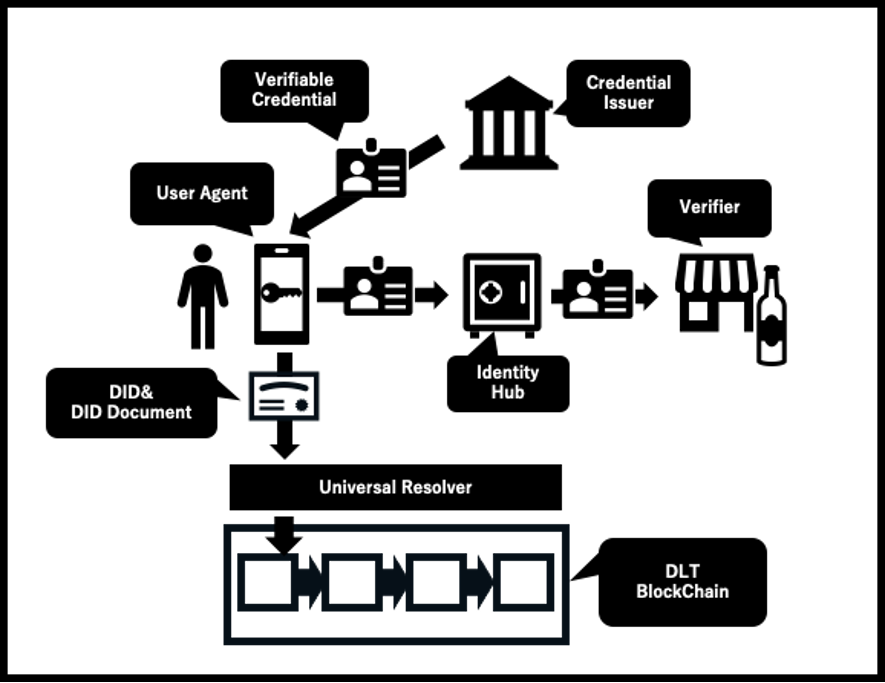
User Agentはスマートフォンのアプリケーション等の形で実装されることが想定されており、ユーザの鍵やDID及びDIDドキュメントの生成の他、Verifiable Credentialの管理やVerifier(検証者)とのやり取り等を行います。User Agent によって生成されたDID/DID Documentは分散台帳やブロックチェーンのようなネットワークに保管されますが、前述のメソッド(=分散台帳の実装)毎の差分を解決するのがUniversal Resolverです。Universal Resolverを介することで、分散台帳側の実装に依存しない形でDIDのやり取りを行うことができます。
Credential Issuerは、DIDの持ち主に対してVerifiable Credentialの発行を行います。学籍証明書のCredentialを発行するのであれば、一般的には学校がCredential Issuerになります。発行されたVerifiable CredentialはUser Agentを介してIdentity Hubに保管されます。Identity Hubは、オフチェーンでセキュリティが確保された保管庫です。常にUser Agentと同期されており、User AgentからVerifiable Credentialの削除の指示があればすぐに削除します。
Verifier(検証者)がユーザの属性を検証したい場合、たとえば学校の売店が、来店者がその学校の生徒であることを検証したい場合、売店は来店者に対して該当するVerifiable Credentialの提示を求めます。売店が来店者によって提示されたVerifiable CredentialのProof部分を検証し、確かに該当の学校が発行した学籍証明書であることを確認することができます。
ユーザは複数のDIDを持つことができます。自分の様々な属性を表す複数のVerifiable Credentialをそれぞれ異なるDIDに対して発行することで、DIDによる「名寄せ」を防ぐことができ、より高いレベルでプライバシーを保護することができます。
まとめ
今回は、SSI/DIDに関連した標準化や実装の動向をご紹介しました。
ご紹介したように現在はまだ様々な団体によって標準化や実装の方法が検討され、PoC等が行われている段階で、本格的に利用されているものは多くありません。ただ、ヨーロッパではSSIとeIDASの整合性についての評価・検討が行われ、また日本でも政策会議の1つである「デジタル市場競争会議」において検討が行われるなど、その存在価値を徐々に増している状況です。
我々も日々その動向をウォッチし、またこのブログ上で共有したいと考えています。
なお、私と神沼が所属する日本クラウドセキュリティアライアンスのBlockChainワーキンググループのIdentityサブワーキンググループより、本ブログに掲載した内容を含むホワイトペーパーを発表予定です。ご期待ください。
![RaspberryPiとAWS IoTを使用した温湿度の可視化[後編]](https://tech.gmogshd.com/wp-content/uploads/2020/11/arch2-375x173.png)
