GMOグローバルサイン・ホールディングスCTO室の@zulfazlihussinです。
私はhakaru.aiの開発チームにてAI開発を担当しております。今回は、最近発表された新しいニューラルネットワークの学習手法、Fourier Analysis Networks (FANs)[1] について、述べたいと思います。
FANsとは
一つのニューラルネットワークのパーセプトロンを多層化したアーキテクチャであるMulti-Layer Perceptrons(MLPs)は、数あるAIモデルの中で、よく使われています。MLPsのアーキテクチャでは、入力データの空間的および局所的な特徴の抽出に重点を置いています。しかし、画像や音声、さらには時系列データには、隠れた周期性やリズムといった特徴も存在します。MLPは入力を独立したものとして扱うため、時間的および連続したパターンを捉えるメカニズムに欠けています。そのため、周期信号における周波数、振幅、位相の変化をモデル化するのが難しいのです。
そこで、Fourier Analysis Networks(FANs)は、フーリエ解析を活用して、従来の手法では見落としがちな信号の周期性や周波数成分を効果的に抽出する新しいアーキテクチャとして注目されています。FANsは、フーリエ変換を通じて入力データを周波数領域にマッピングし、これらの特徴を直接学習することで、より効率的かつ安定したモデルの構築を可能にします。
フーリエ解析とは
数学や工学、さらにはAIの分野で広く活用される「フーリエ解析」とは、複雑な信号やデータを単純な周期関数(正弦波や余弦波)の重ね合わせとして表現する手法です。
フーリエ解析の核心は、任意の周期的な信号を複数の正弦波 a(n) と余弦波 b(n) に分解できるという点です。これにより、複雑な波形も「どの周波数成分がどのくらい寄与しているか」という形で、パターンとして置き換えることが可能となります。
分解のための代表的な手法が「フーリエ変換」です。これを用いると、時間領域のデータを周波数領域に変換でき、信号に含まれる周期性やリズムを一目で把握することができます。例えば、音声データなら、どの音程やリズムが強く現れているかを分析することができます。
ニューラルネットワークでフーリエ変換を処理する時の課題
入力信号にフーリエ変換を適用することで、信号に含まれる周期性や周波数成分を明確に抽出します。フーリエ級数展開において、角周波数項 ω(n)=2πn/T
と各周波数成分(正弦波 a(n) や余弦波 b(n))のフーリエ係数を学習可能なパラメータとして扱えます。これにより、空間領域での処理では捉えにくい情報を効果的に利用できるようになります。
抽出された周波数成分は、ニューラルネットワークの各層で処理され、異なる周波数帯域ごとに特徴が強調されます。高周波成分と低周波成分のバランスを取ることで、より堅牢な表現が得られ、学習の安定性も向上します。
しかし、ニューラルネットワークにフーリエ級数の方程式を適用して深いネットワークを構築しようとすると、課題があります。
ニューラルネットワークは、層を重ねると、フーリエ級数展開の中で角周波数項 ω(n)=2πn/T の学習に過剰に集中してしまう傾向があります。角周波数項 ω(n)=2πn/T の学習とフーリエ係数 a(n) や b(n)の学習が順次適用されるため、中間層がフーリエ係数 a(n) や b(n) の調整に寄与できず、主に角周波数項 ω(n)=2πn/T の学習に偏ってしまうという課題があります。
そのため、重要な要素であるフーリエ係数 a(n) や b(n) を十分に学習できなくなります。これは、最終層でのみ適用されるため、中間層やネットワークの深さを増やしても、フーリエ係数の詳細な調整に寄与しないからです。
ニューラルネットワークでフーリエ変換を適応するには
フーリエ変換をニューラルネットワークに適用するには、どのようにすればよいでしょうか?
FANs(Fourier Analysis Networks)のアプローチとして重要なのは、順次学習ではなく、同時に学習することです。具体的には、角周波数項 ω(n)=2πn/T の学習とフーリエ係数 a(n) や b(n) の学習を分離し、各層で同時に学習します。
中間層で同時に学習することにより、従来の順次学習による偏りの問題が解消され、各層が周期性のモデリング(つまり、角周波数項 ω(n) の学習)とフーリエ係数の精緻化(a(n) や b(n) の学習)の両方に貢献できるようになります。
これを実現することで、より効果的に入力信号の周期性やリズムを学習できるようになります。
FANsでは何ができる?
効率的なパターン認識
FANsの大きな強みは、データ中に隠れた周期性やパターンを効率的に認識できることです。フーリエ解析を活用することで、データの背景に潜む規則性を明らかにし、より深い洞察を得ることが可能です。これにより、特に時系列データの予測や信号処理といった分野で大きな効果を発揮します。
学習の安定性向上
AIモデルの学習において避けたい問題の一つが過学習ですが、FANsはこのリスクを低減させます。周波数成分を直接扱うことにより、モデルはデータの本質的なパターンをより安定的に学習します。これにより、学習プロセス全体の安定性が向上し、予測精度も向上します。
高次元データへの適応
今日のデータセットは、ますます複雑で高次元化しています。FANsは、このような複雑なデータに対しても有効に機能します。多次元のデータ空間における隠れた構造を解析し、実用的な問題解決における新たな道を切り開きます。この適応性の高さは、さまざまな業界での実装において非常に有用です。
MLPsとは何が違う?
MLPsでは、全結合層による非線形変換を通じてデータ全体のパターンを学習しますが、局所的な周期性や繰り返しパターンの抽出には限界があります。一方、FANsでは、フーリエ変換を用いて入力データを周波数領域に変換し、そこで得られる周期成分やリズム情報を直接学習します。これにより、従来の手法では捉えにくかったデータのグローバルな特徴やパターンを効果的に抽出することが可能となります。
また、学習の安定性と計算効率の面では、MLPsは学習時に局所的な最適解に陥りやすく、過学習のリスクを伴う場合もあります。さらに、ネットワークの深さやパラメータ数が増えると、計算負荷も高まります。しかし、FANsでは、周波数領域での情報処理を活用することで、入力信号の本質的な周期性やパターンを捉えやすく、より堅牢な特徴表現を実現できます。これにより、学習過程での安定性が向上し、複雑なデータに対する性能が改善される可能性があります。
FANsを実装する
今回はここの記事を参考にして、実際にFANsを実装してみました。
まず、以下の方程式に基づいて、1から10の一様分布から得られるサンプルにガウスノイズを加えたデータセットを生成するクラスを作成します。
y = cos(1.4πx) + sin(0.7πx) + cos(0.5πx) + sin(2.2πx) …. 方程式(1)
import numpy as np
import torch
class MyDataset(Dataset):
def __init__(self, num_samples, noise_level):
# 1から10までの間にランダム数を生成し、xとする_
self.x = np.random.uniform(0, 10, (num_samples, 1)).astype(np.float32)
#ノイズと追加
noise = noise_level * np.random.randn(*self.y.shape).astype(np.float32)
#方程式(1)をyとして生成する(noiseも含む)
self.y = (np.cos(1.4 * np.pi * self.x) + (np.sin(0.7 * np.pi * self.x) + np.cos(0.5 * np.pi * self.x)).astype(np.float32) + np.sin(2.2 * np.pi * self.x)).astype(np.float32) + noise
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
x = torch.from_numpy(self.x[idx])
y = torch.from_numpy(self.y[idx])
return x, y
一つののFANモデルの層を定義するためのクラスを作成します。
import torch.nn as nn
class FANLayer(nn.Module):
def __init__(self, in_features, d_p, d_p_bar, activation=nn.GELU()):
super().__init__()
self.Wp = nn.Parameter(torch.randn(in_features, d_p))
self.Wp_bar = nn.Parameter(torch.randn(in_features, d_p_bar))
self.Bp_bar = nn.Parameter(torch.zeros(d_p_bar))
self.activation = activation
def forward(self, x):
cos_term = torch.cos(torch.matmul(x, self.Wp))
sin_term = torch.sin(torch.matmul(x, self.Wp))
non_periodic_term = self.activation(torch.matmul(x, self.Wp_bar) + self.Bp_bar)
return torch.cat([cos_term, sin_term, non_periodic_term], dim=-1)
複数のFAN層を追加し、FANモデルのクラスを作成します。
class FAN(nn.Module):
def __init__(self, in_features, hidden_dim, num_layers, activation=nn.GELU()):
super().__init__()
self.num_layers = num_layers
self.layers = nn.ModuleList()
# 論文の実験では、d_pの値をhidden_dimの1/4で設定しました。
d_p = hidden_dim // 4
d_p_bar = hidden_dim
# 隠れ層
for _ in range(num_layers - 1):
self.layers.append(FANLayer(in_features, d_p, d_p_bar, activation))
in_features = 2 * d_p + d_p_bar
# 出力層のパラメーター
self.WL = nn.Parameter(torch.randn(in_features, 1))
self.BL = nn.Parameter(torch.zeros(1))
def forward(self, x):
for layer in self.layers:
x = layer(x)
return torch.matmul(x, self.WL) + self.BL
MLPと比較したいので、MLP層を定義するクラスを作成します。
class MLP(nn.Module):
def __init__(self, in_features, hidden_dim, num_layers):
super().__init__()
layers = []
for _ in range(num_layers - 1):
layers.append(nn.Linear(in_features, hidden_dim))
layers.append(nn.GELU())
in_features = hidden_dim
layers.append(nn.Linear(hidden_dim, 1))
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
学習するためのクラスを作成します。
from torch.utils.data import DataLoader, Dataset
from tqdm import tqdm
def train_model(train_dataset, val_dataset, model, epochs, batch_size, lr, model_name):
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
train_losses = []
val_losses = []
for epoch in tqdm(range(1, epochs + 1), desc=f"Training {model_name}"):
model.train()
epoch_train_loss = 0.0
for x_batch, y_batch in train_dataloader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
optimizer.zero_grad()
preds = model(x_batch)
loss = criterion(preds, y_batch)
loss.backward()
optimizer.step()
epoch_train_loss += loss.item() * x_batch.size(0)
model.eval()
epoch_val_loss = 0.0
with torch.no_grad():
for x_batch, y_batch in val_dataloader:
x_batch, y_batch = x_batch.to(device), y_batch.to(device)
preds = model(x_batch)
loss = criterion(preds, y_batch)
epoch_val_loss += loss.item() * x_batch.size(0)
epoch_train_loss /= len(train_dataset)
epoch_val_loss /= len(val_dataset)
train_losses.append(epoch_train_loss)
val_losses.append(epoch_val_loss)
if epoch % 50 == 0 or epoch == 1 or epoch == epochs:
print(f"Epoch {epoch}/{epochs} - {model_name} Training Loss: {epoch_train_loss:.6f}, Validation Loss: {epoch_val_loss:.6f}")
return train_losses, val_losses
学習を実行します。
from torch.utils.data import random_split
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
print(f"FAN model is on device: {next(fan_model.parameters()).device}")
print(f"MLP model is on device: {next(mlp_model.parameters()).device}")
#データセットの準備。ノイズは0.5にしています
dataset = MyDataset(num_samples=1000, noise_level=0.5)
# 学習データとバリデーションデータ
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
# FANsのモデルとMLPsのモデルの初期化
fan_model = FAN(in_features=1, hidden_dim=32, num_layers=3).to(device)
mlp_model = MLP(in_features=1, hidden_dim=32, num_layers=3).to(device)
# FANsで学習
fan_train_losses, fan_val_losses = train_model(train_dataset, val_dataset, fan_model, epochs=500, batch_size=32, lr=0.001, model_name="FAN")
# MLPsで学習
mlp_train_losses, mlp_val_losses = train_model(train_dataset, val_dataset, mlp_model, epochs=500, batch_size=32, lr=0.001, model_name="MLP")
学習したFANsモデルとMLPsモデルを比較して、evaluate_modelで評価します。
import matplotlib.pyplot as plt
def evaluate_model(fan_model, mlp_model):
# 方程式(1)
x_test = torch.linspace(0, 10, 1000).reshape(-1, 1).float().to(device)
y_test = self.y = (np.cos(1.4 * np.pi * self.x) + (np.sin(0.7 * np.pi * self.x) + np.cos(0.5 * np.pi * self.x)).astype(np.float32) + np.sin(2.2 * np.pi * self.x)).astype(np.float32)
fan_model.eval()
mlp_model.eval()
with torch.no_grad():
fan_pred = fan_model(x_test).cpu().numpy()
mlp_pred = mlp_model(x_test).cpu().numpy()
plt.figure(figsize=(12, 6))
plt.plot(x_test.cpu().numpy(), y_test, label="方程式(1)の値", color="black", linestyle="dashed")
plt.plot(x_test.cpu().numpy(), fan_pred, label="FANs での予測", color="blue", alpha=0.7)
plt.plot(x_test.cpu().numpy(), mlp_pred, label="MLPs での予測", color="red", alpha=0.7)
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.show()
evaluate_model(fan_model, mlp_model)
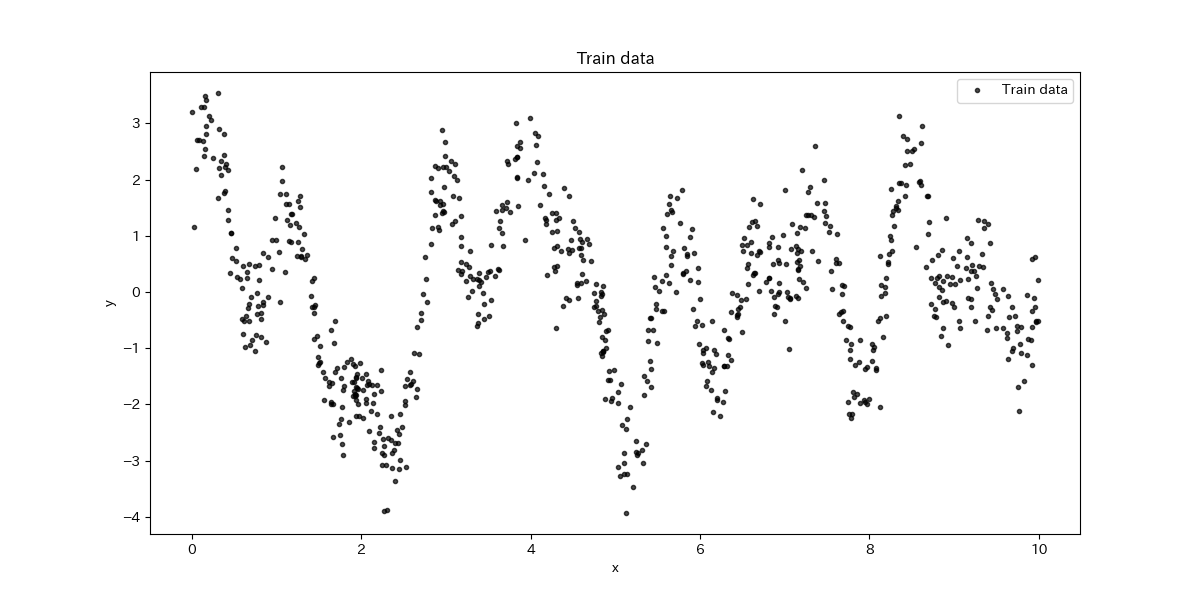
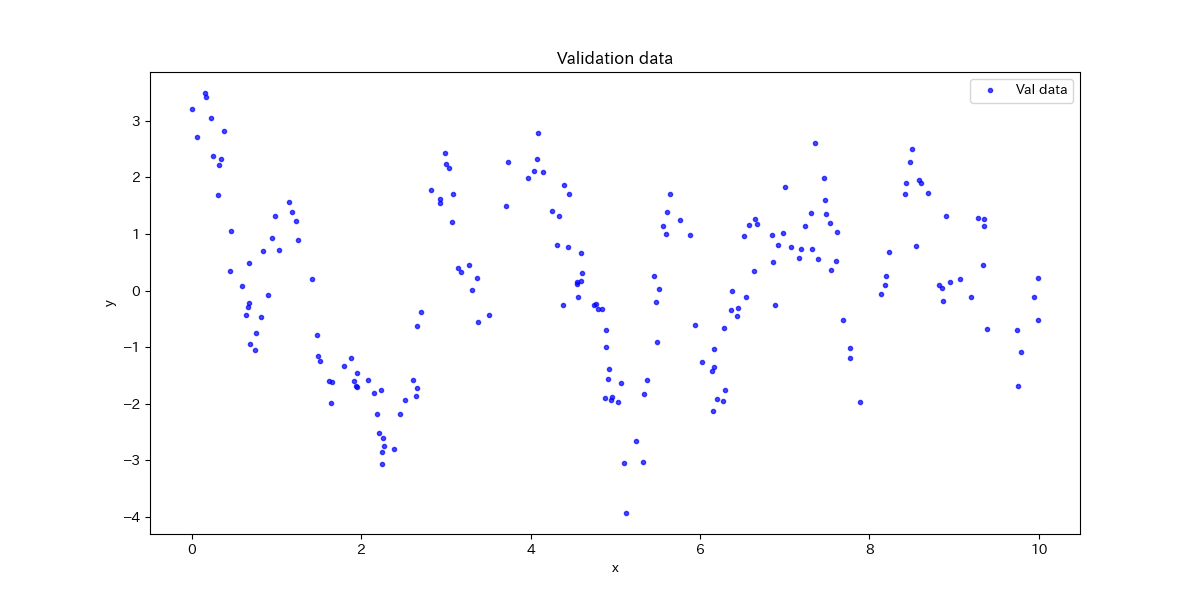
学習データと評価用のテストデータ
評価結果
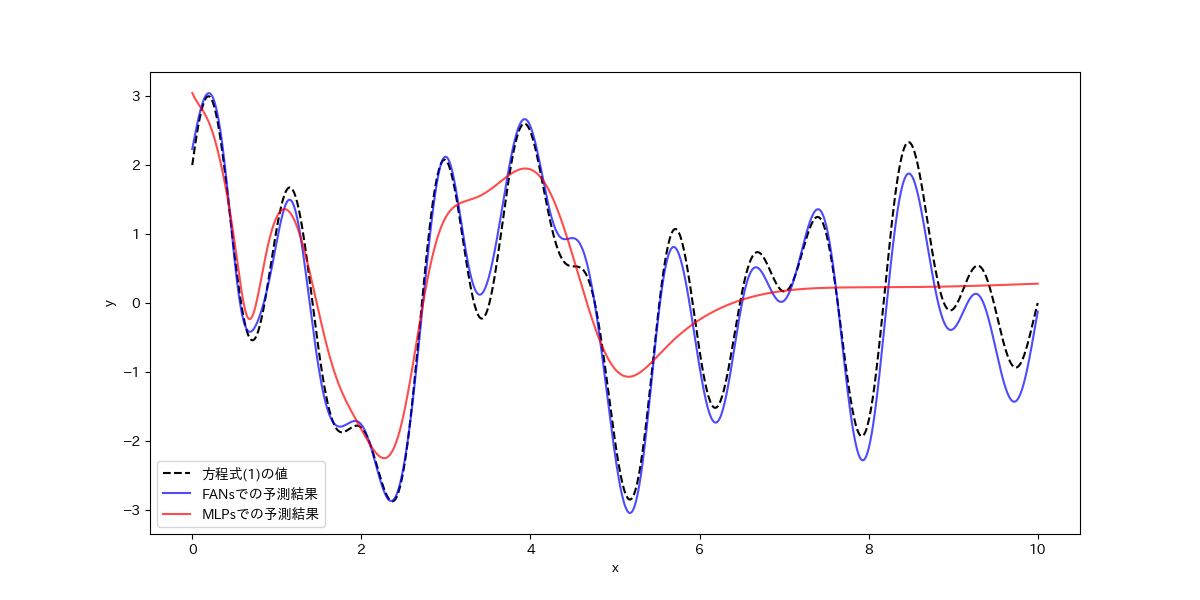
予測結果の通り、FANsモデルで予測した結果は、方程式(1)の線に沿って正確に予測することが確認できました。一方、MLPsモデルの予測結果を見ると、周期的な信号に対する特徴学習には限界があると感じました。
まとめ
FANsは、従来のMLPsが空間領域で特徴を捉えるのに対し、データの周期性やグローバルなパターンを周波数領域で直接学習できるという大きな特徴があります。これにより、複雑なパターンの認識や安定した学習を実現する可能性が期待できると感じました。今後、これらの特性を最大限に活かし、画像認識のタスクにも応用したいと考えています。
この記事は以上になります。最後までお読みいただきありがとうございました。